
Elasticsearch
MySql存在的问题:
查询效率较低
由于数据库模糊查询不走索引,在数据量较大的时候,查询性能很差。
数据库模糊查询随着表数据量的增多,查询性能的下降会非常明显,而搜索引擎的性能则不会随着数据增多而下降太多。目前仅10万不到的数据量差距就如此明显,如果数据量达到百万、千万、甚至上亿级别,这个性能差距会非常夸张。
功能单一
数据库的模糊搜索功能单一,匹配条件非常苛刻,必须恰好包含用户搜索的关键字。而在搜索引擎中,用户输入出现个别错字,或者用拼音搜索、同义词搜索都能正确匹配到数据。
综上,在面临海量数据的搜索,或者有一些复杂搜索需求的时候,推荐使用专门的搜索引擎来实现搜索功能。
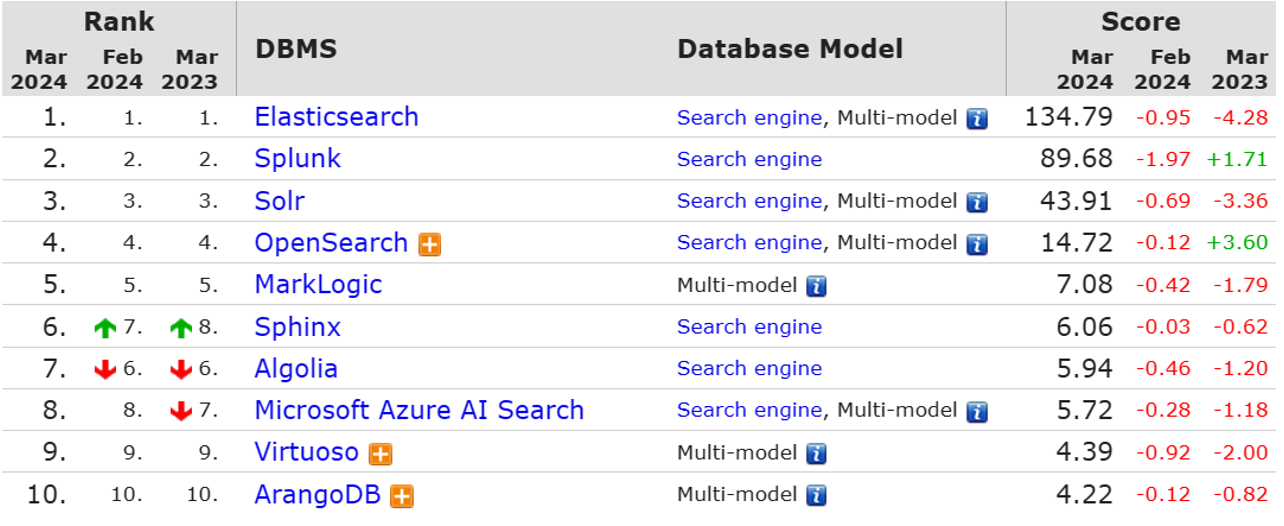
目前全球的搜索引擎技术排名如下:
认识ES
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/ 。
Lucene的优势:
- 易扩展
- 高性能(基于倒排索引)
- 2004年Shay Banon基于Lucene开发了Compass
- 2010年Shay Banon 重写了Compass,取名为Elasticsearch。
- 官网地址: https://www.elastic.co/cn/ ,目前最新的版本是:8.x.x
- elasticsearch具备下列优势:
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
Elasticsearch:用于数据存储、计算和搜索Logstash/Beats:用于数据收集Kibana:用于数据可视化 整套技术栈被称为ELK,经常用来做日志收集、系统监控和状态分析等等:
整套技术栈的核心就是用来存储、搜索、计算的Elasticsearch
我们要安装的内容包含2部分:
elasticsearch:存储、搜索和运算kibana:图形化展示
首先Elasticsearch不用多说,是提供核心的数据存储、搜索、分析功能的。
然后是Kibana,Elasticsearch对外提供的是Restful风格的API,任何操作都可以通过发送http请求来完成。不过http请求的方式、路径、还有请求参数的格式都有严格的规范。这些规范我们肯定记不住,因此我们要借助于Kibana这个服务。
Kibana是elastic公司提供的用于操作Elasticsearch的可视化控制台。它的功能非常强大,包括:
- 对Elasticsearch数据的搜索、展示
- 对Elasticsearch数据的统计、聚合,并形成图形化报表、图形
- 对Elasticsearch的集群状态监控
- 它还提供了一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示
安装ES
上传好我们的镜像
docker load -i es.tardocker load -i kibana.tar通过下面的Docker命令即可安装单机版本的elasticsearch:
docker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network hm-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.12.19200端口:我们访问的http端口
9300端口:将来若有集群,集群间通讯端口
注意,这里我们采用的是elasticsearch的7.12.1版本,由于8以上版本的JavaAPI变化很大,在企业中应用并不广泛,企业中应用较多的还是8以下的版本。
查看下运行日志
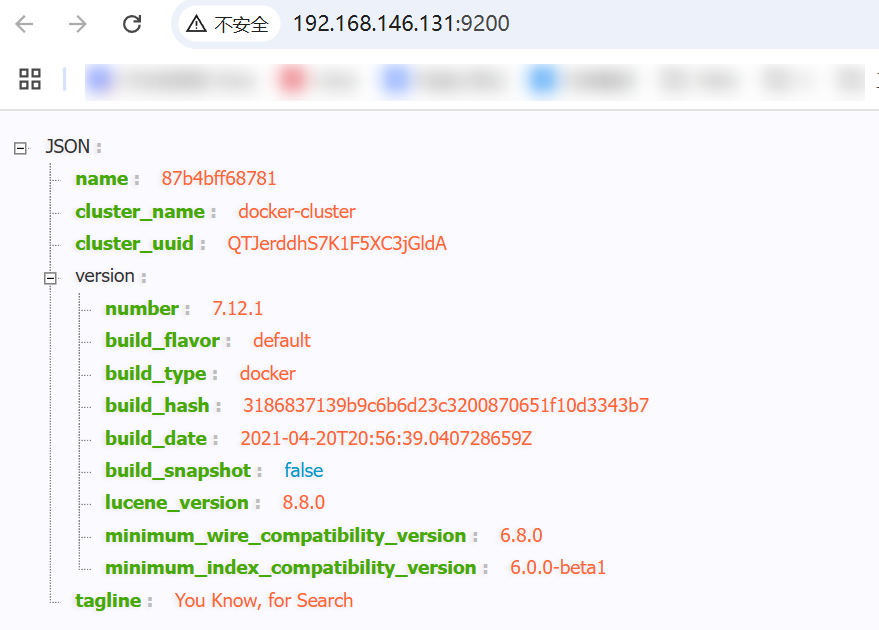
docker logs -f es安装完成后,访问9200端口,即可看到响应的Elasticsearch服务的基本信息
访问该地址:http://192.168.146.131:9200/
安装Kibana
kibana的作用:方便的操作es(通过发送请求的方式)
通过下面的Docker命令,即可部署Kibana:
docker run -d \--name kibana \-e ELASTICSEARCH_HOSTS=http://es:9200 \--network=hm-net \-p 5601:5601 \kibana:7.12.1TIP-e 环境变量配的是es的地址,用于操作es;该地址写的是
es,这是容器名,要根据es部署时的容器名来定;当然这里也可以写虚拟机ip地址;注意es与kibana网络也必须在同一个网络下
安装完成后,直接访问5601端口, http://192.168.146.131:5601/
选择Explore on my own之后,进入主页面:
然后选中Dev tools,进入开发工具页面:
倒排索引
elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。
倒排索引的概念是基于MySQL这样的正向索引而言的。
正向索引
我们先来回顾一下正向索引。 例如有一张名为tb_goods的表:
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| … | … | … |
其中的id字段已经创建了索引,由于索引底层采用了B+树结构,因此我们根据id搜索的速度会非常快。但是其他字段例如title,只在叶子节点上存在。
因此要根据title搜索的时候只能遍历树中的每一个叶子节点,判断title数据是否符合要求。
比如用户的SQL语句为:
select * from tb_goods where title like '%手机%';那搜索的大概流程如图:
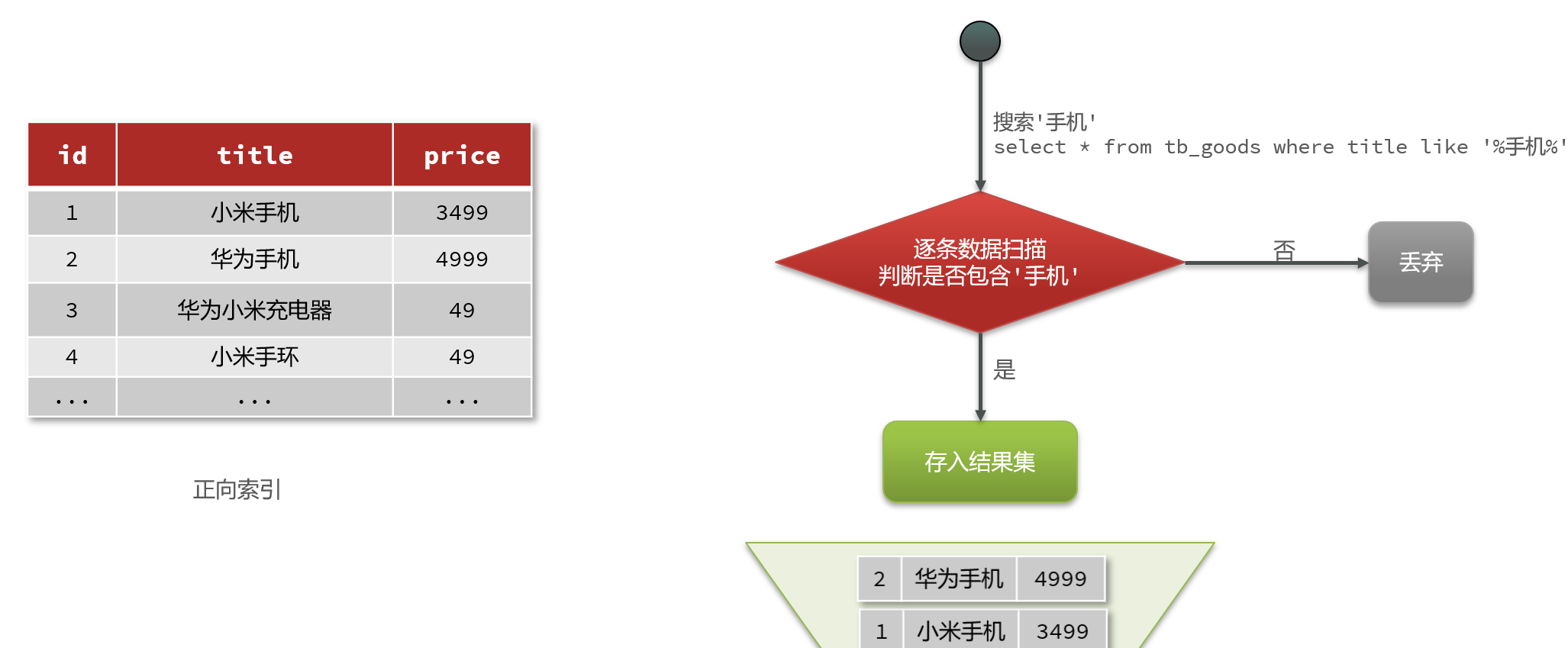
说明:
- 1)检查到搜索条件为like ‘%手机%‘,需要找到title中包含手机的数据
- 2)逐条遍历每行数据(每个叶子节点),比如第1次拿到id为1的数据
- 3)判断数据中的title字段值是否符合条件
- 4)如果符合则放入结果集,不符合则丢弃
- 5)回到步骤1
综上,根据id精确匹配时,可以走索引,查询效率较高。而当搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):文档按照语义分成的词语;对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
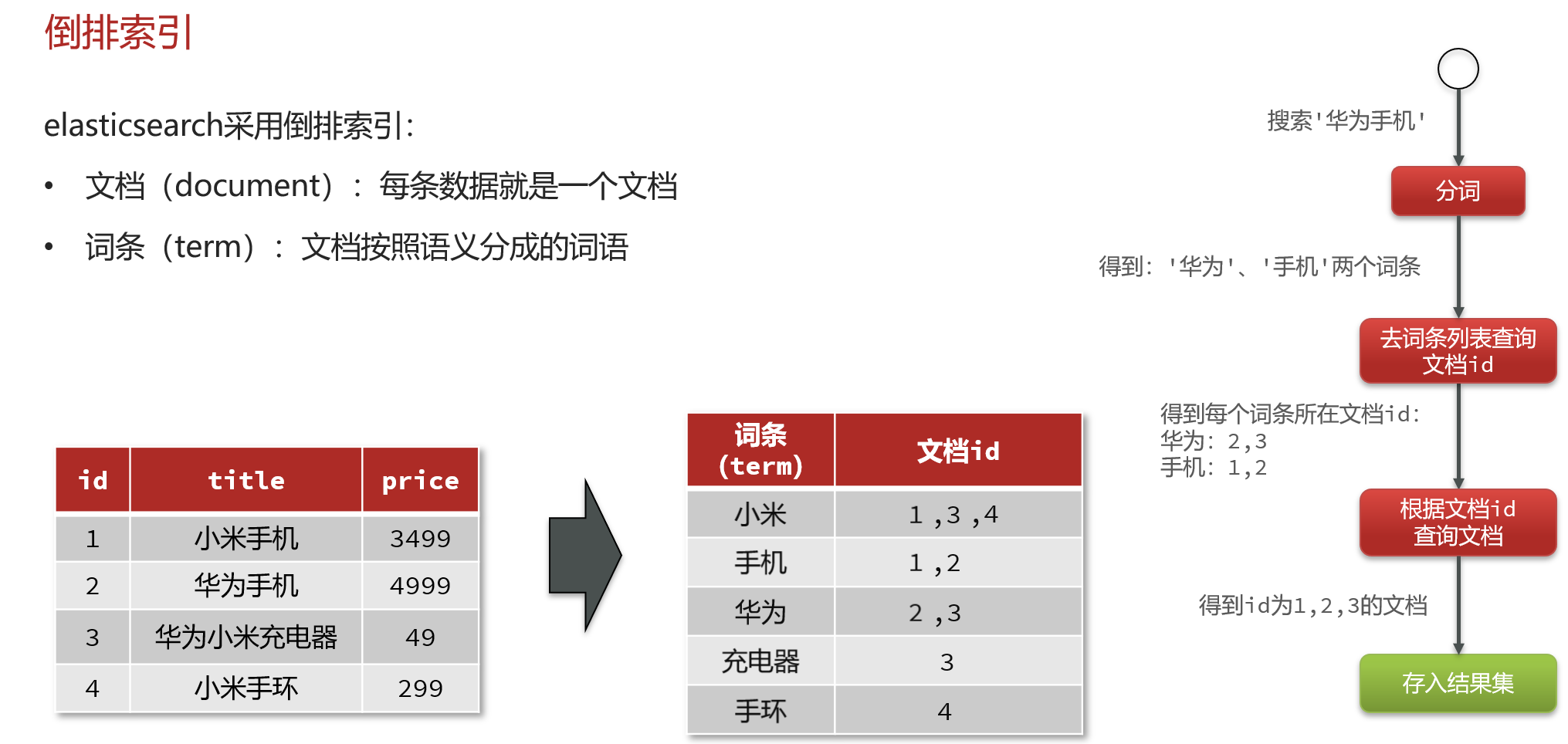
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下:
- 将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建正向索引 此时形成的这张以词条为索引的表,就是倒排索引表,两者对比如下:
倒排索引的搜索流程如下(以搜索”华为手机”为例),如图:
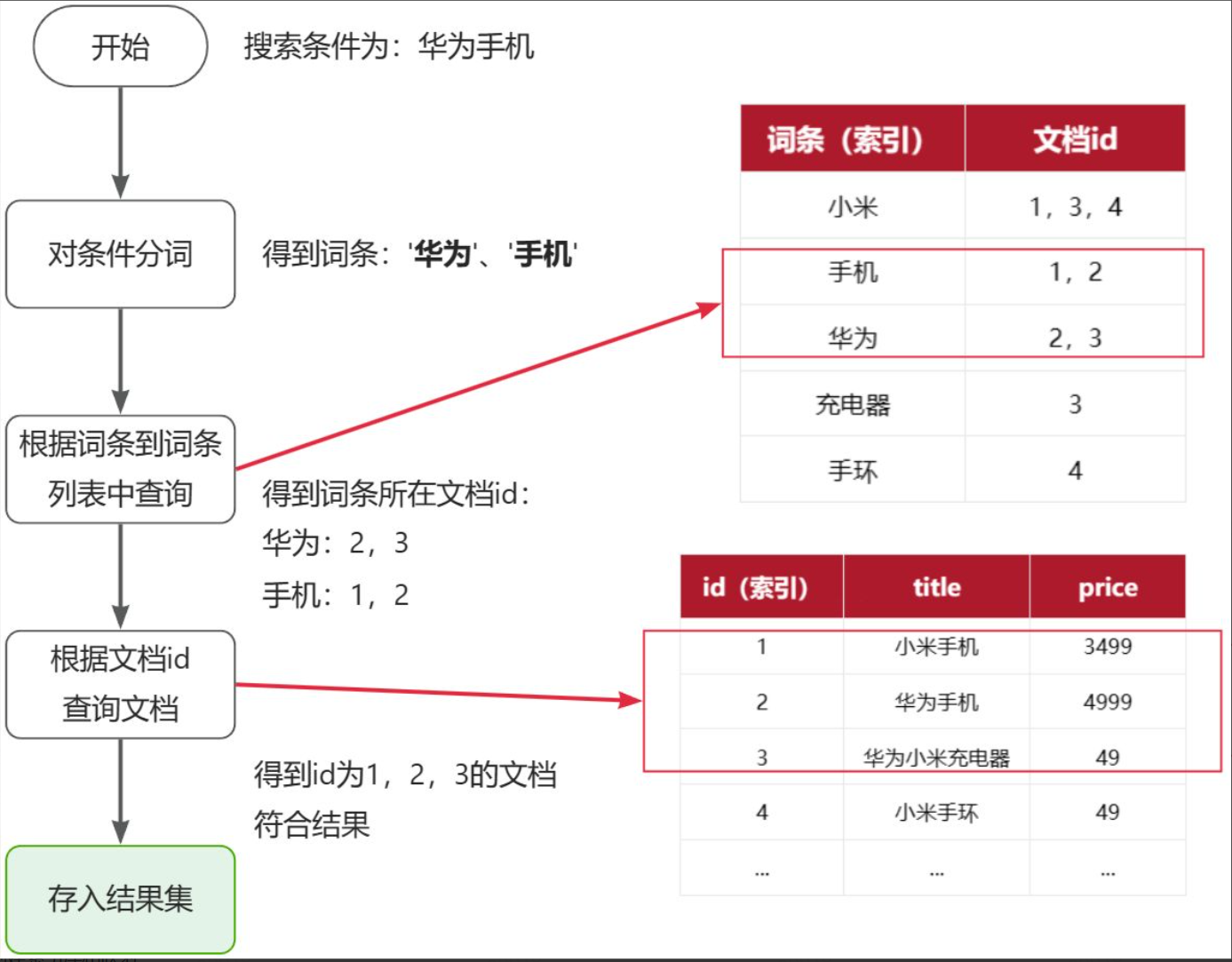
流程描述:
- 1)用户输入条件”华为手机”进行搜索。
- 2)对用户输入条件分词,得到词条:华为、手机。
- 3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
- 4)拿着文档
id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
总结
什么是文档和词条?
- 每一条数据就是一个文档
- 对文档中的内容分词,得到的词语就是词条
什么是正向索引?
- 基于文档id创建索引。根据id查询快,但是查询词条时必须先找到文档,而后判断是否包含词条
什么是倒排索引?
- 对文档内容分词,对词条创建索引,并记录词条所在文档的id。查询时先根据词条查询到文档id,而后根据文档id查询文档
IK分词器
中文分词往往需要根据语义分析,比较复杂,这就需要用到中文分词器,例如IK分词器。IK分词器是林良益在2006年开源发布的,其采用的正向迭代最细粒度切分算法一直沿用至今。
其安装的方式也比较简单
1. 下载ik分词器这个插件
github 链接:https://github.com/medcl/elasticsearch-analysis-ik
github 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
2. 方案1
运行一个命令即可:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip然后重启es容器:
docker restart es2. 方案2
如果网速较差,也可以选择离线安装。 首先,查看之前安装的Elasticsearch容器的plugins数据卷目录:
docker volume inspect es-plugins可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。我们需要把IK分词器上传至这个目录。
找到ik分词器插件,安装的是7.12.1版本的ik分词器压缩文件;
然后上传至虚拟机的/var/lib/docker/volumes/es-plugins/_data这个目录:
最后,重启es容器:
docker restart es查看下日志
docker logs -f es可以看到如下字样
"message": "loaded plugin [analysis-ik]" }使用IK分词器
IK分词器包含两种模式:
ik_smart:智能语义切分ik_max_word:最细粒度切分
我们在Kibana的DevTools上来测试分词器,首先测试Elasticsearch官方提供的标准分词器:
POST /_analyze{ "analyzer": "standard", "text": "黑马程序员学习java太棒了"}{ "tokens" : [ { "token" : "黑", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "马", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "程", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "序", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "员", "start_offset" : 4, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 4 }, { "token" : "学", "start_offset" : 5, "end_offset" : 6, "type" : "<IDEOGRAPHIC>", "position" : 5 }, { "token" : "习", "start_offset" : 6, "end_offset" : 7, "type" : "<IDEOGRAPHIC>", "position" : 6 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "太", "start_offset" : 11, "end_offset" : 12, "type" : "<IDEOGRAPHIC>", "position" : 8 }, { "token" : "棒", "start_offset" : 12, "end_offset" : 13, "type" : "<IDEOGRAPHIC>", "position" : 9 }, { "token" : "了", "start_offset" : 13, "end_offset" : 14, "type" : "<IDEOGRAPHIC>", "position" : 10 } ]}可以看到,标准分词器智能1字1词条,无法正确对中文做分词。
我们再测试IK分词器:
POST /_analyze{ "analyzer": "ik_smart", "text": "黑马程序员学习java太棒了"}结果如下
{ "tokens" : [ { "token" : "黑马", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "程序员", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 1 }, { "token" : "学习", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 2 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "ENGLISH", "position" : 3 }, { "token" : "太棒了", "start_offset" : 11, "end_offset" : 14, "type" : "CN_WORD", "position" : 4 } ]}POST /_analyze{ "analyzer": "ik_max_word", "text": "黑马程序员学习java太棒了"}结果如下
{ "tokens" : [ { "token" : "黑马", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "程序员", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 1 }, { "token" : "程序", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "员", "start_offset" : 4, "end_offset" : 5, "type" : "CN_CHAR", "position" : 3 }, { "token" : "学习", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 4 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "ENGLISH", "position" : 5 }, { "token" : "太棒了", "start_offset" : 11, "end_offset" : 14, "type" : "CN_WORD", "position" : 6 }, { "token" : "太棒", "start_offset" : 11, "end_offset" : 13, "type" : "CN_WORD", "position" : 7 }, { "token" : "了", "start_offset" : 13, "end_offset" : 14, "type" : "CN_CHAR", "position" : 8 } ]}拓展词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“泰裤辣”,“传智播客” 等。
POST /_analyze{ "analyzer": "ik_max_word", "text": "传智播客开设大学,真的泰裤辣!"}可以看到,传智播客和泰裤辣都无法正确分词。
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:/var/lib/docker/volumes/es-plugins/_data/elasticsearch-analysis-ik-7.12.1/config/
IKAnalyzer.cfg.xml文件
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>3)在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
传智播客泰裤辣4)重启elasticsearch
docker restart es
# 查看 日志docker logs -f es再次测试,可以发现传智播客和泰裤辣都正确分词了:
{ "tokens" : [ { "token" : "传智播客", "start_offset" : 0, "end_offset" : 4, "type" : "CN_WORD", "position" : 0 }, { "token" : "开设", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 1 }, { "token" : "大学", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 2 }, { "token" : "真的", "start_offset" : 9, "end_offset" : 11, "type" : "CN_WORD", "position" : 3 }, { "token" : "泰裤辣", "start_offset" : 11, "end_offset" : 14, "type" : "CN_WORD", "position" : 4 } ]}总结
分词器的作用是什么?
- 创建倒排索引时,对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
ik_smart:智能切分,粗粒度ik_max_word:最细切分,细粒度IK分词器
如何拓展分词器词库中的词条?
- 利用
config目录的IkAnalyzer.cfg.xml文件添加拓展词典 - 在词典中添加拓展词条
索引库操作
基础概念
索引(index):相同类型的文档的集合
映射(mapping):索引中文档的字段约束信息,类似表的结构约束

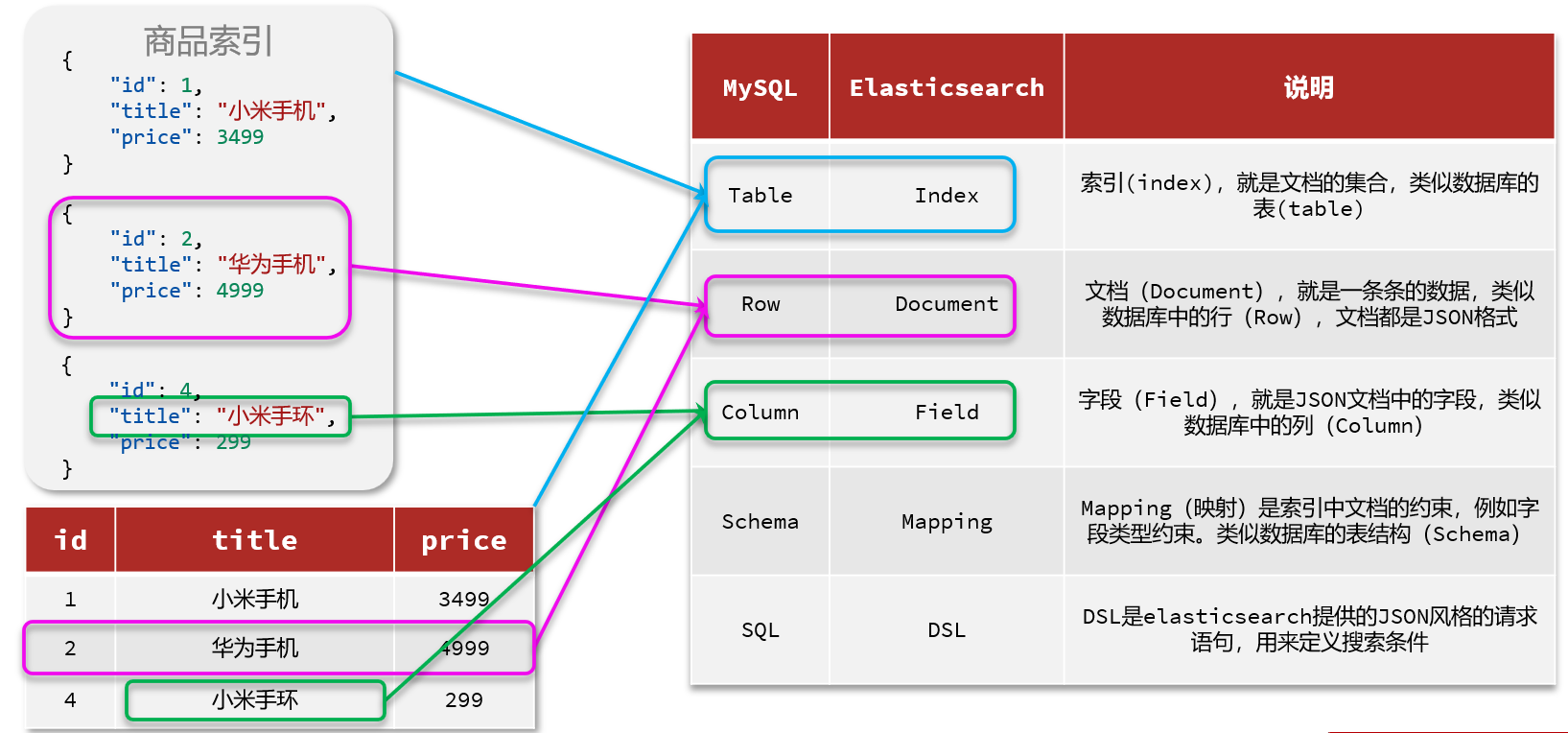
Index就类似数据库表,Mapping映射就类似表的结构。我们要向es中存储数据,必须先创建Index和Mapping
Mapping映射属性
Mapping是对索引库中文档的约束,常见的Mapping属性包括:
type:字段数据类型,常见的简单类型有:- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
index:是否创建索引,默认为trueanalyzer:使用哪种分词器properties:该字段的子字段
例如下面的json文档:
{ "age": 21, "weight": 52.1, "isMarried": false, "info": "黑马程序员Java讲师", "email": "zy@itcast.cn", "score": [99.1, 99.5, 98.9], "name": { "firstName": "云", "lastName": "赵" }}- score是float类型
- 如果对score进行排序,排序时,ES很智能,降序选取值最大的,升序选取值最小的
- 是否需要创建索引,要看该字段是否需要搜索和排序
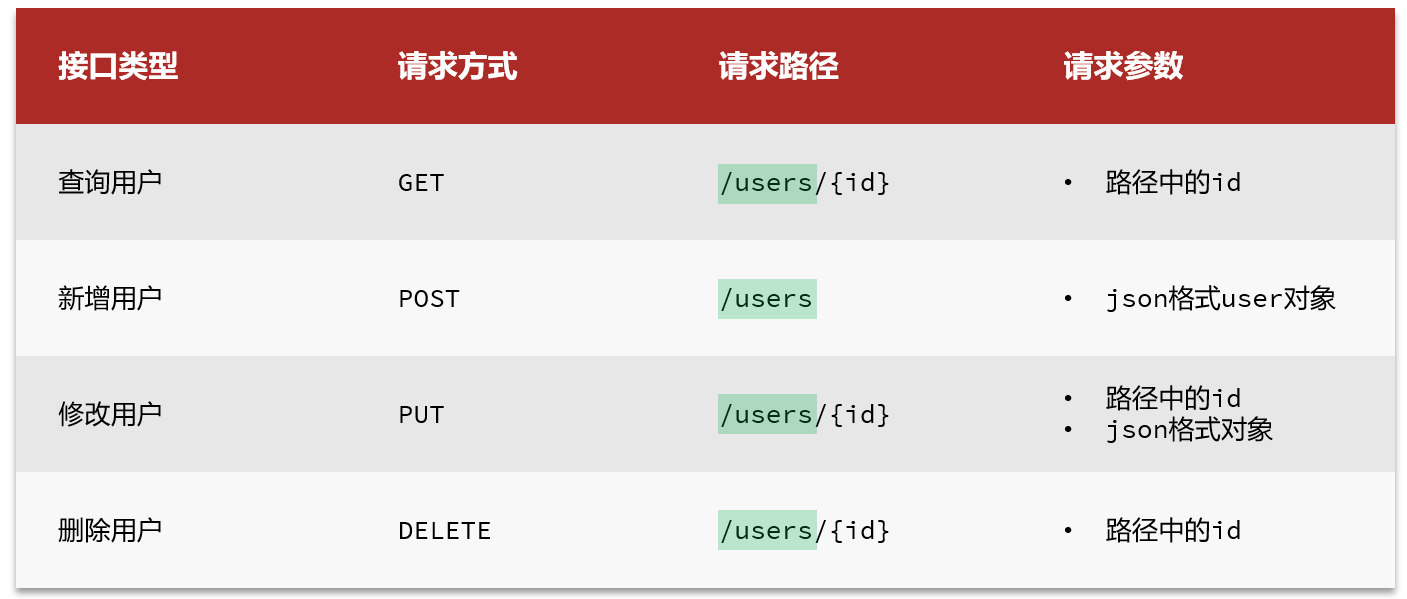
索引库的CRUD
由于Elasticsearch采用的是Restful风格的API,因此其请求方式和路径相对都比较规范,而且请求参数也都采用JSON风格。
创建索引库和映射
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
格式:
PUT /索引库名称{ "mappings": { "properties": { "字段名":{ "type": "text", "analyzer": "ik_smart" }, "字段名2":{ "type": "keyword", "index": "false" }, "字段名3":{ "properties": { "子字段": { "type": "keyword" } } }, // ...略 } }}示例:
PUT /heima{ "mappings": { "properties": { "info":{ "type":"text", "analyzer": "ik_smart" }, "age":{ "type": "byte" }, "email":{ "type": "keyword", "index": false }, "name":{ "type": "object", "properties": { "firstName":{ "type":"keyword" }, "lastName":{ "type":"keyword" } } } } }}执行结果
{ "acknowledged" : true, "shards_acknowledged" : true, "index" : "heima"}查询索引库
基本语法:
- 请求方式:GET
- 请求路径:/索引库名
- 请求参数:无
格式:
GET /索引库名示例:
GET /heima删除索引库
语法:
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
格式:
DELETE /索引库名示例
DELETE /heima修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
语法说明:
PUT /索引库名/_mapping{ "properties": { "新字段名":{ "type": "integer" } }}示例:
PUT /heima/_mapping{ "properties": { "age":{ "type": "integer" } }}PUT /heima/_mapping{ "properties":{ "otherInfo":{ "type":"text" } }}总结
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 修改索引库,添加字段:PUT /索引库名/_mapping
可以看到,对索引库的操作基本遵循的Restful的风格,因此API接口非常统一,方便记忆。
文档CRUD
有了索引库,接下来就可以向索引库中添加数据了。
新增文档
语法:
POST /索引库名/_doc/文档id{ "字段1": "值1", "字段2": "值2", "字段3": { "子属性1": "值3", "子属性2": "值4" },}示例:
POST /heima/_doc/1{ "info": "zxyang study java", "email": "zzyang.cn", "name": { "firstName": "云", "lastName": "赵" }}响应结果:
{ "_index" : "heima", "_type" : "_doc", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 2}
// 下划线代表内置变量,跟Python类似查询文档
根据Restful风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
GET /{索引库名称}/_doc/{id}示例:
GET /heima/_doc/1响应
{ "_index" : "heima", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 2, "found" : true, "_source" : { "info" : "zxyang study java", "email" : "zzyang.cn", "name" : { "firstName" : "云", "lastName" : "赵" } }}删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
DELETE /{索引库名}/_doc/id值示例:
DELETE /heima/_doc/1响应:
{ "_index" : "heima", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "deleted", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 2}修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 局部修改:修改文档中的部分字段
全量修改
全量修改,会删除旧文档,添加新文档
全量修改是覆盖原来的文档,其本质是两步操作:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id{ "字段1": "值1", "字段2": "值2", // ... 略}示例:
PUT /heima/_doc/1{ "info": "zxyang STUDY java", "email": "ZZyang.cn", "name": { "firstName": "云", "lastName": "赵" }}响应:
{ "_index" : "heima", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 3, "_primary_term" : 2}局部修改
也叫增量修改, 局部修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id{ "doc": { "字段名": "新的值", }}示例:
POST /heima/_update/1{ "doc": { "email": "aaaa.cc" }}响应:
{ "_index" : "heima", "_type" : "_doc", "_id" : "1", "_version" : 3, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 4, "_primary_term" : 2}注意:不要使用全量修改的方式去修改部分字段,这样会导致修改后的数据,字段仅剩你修改的那一个了
总结
文档操作有哪些?
- 创建文档:
POST /{索引库名}/_doc/文档id{ json文档 } - 查询文档:
GET /{索引库名}/_doc/文档id - 删除文档:
DELETE /{索引库名}/_doc/文档id - 修改文档:
- 全量修改:
PUT /{索引库名}/_doc/文档id { json文档 } - 局部修改:
POST /{索引库名}/_update/文档id { "doc": {字段}}
- 全量修改:
批量处理
批处理采用POST请求,基本语法如下:
POST _bulk{ "index" : { "_index" : "test", "_id" : "1" } }{ "field1" : "value1" }{ "delete" : { "_index" : "test", "_id" : "2" } }{ "create" : { "_index" : "test", "_id" : "3" } }{ "field1" : "value3" }{ "update" : {"_id" : "1", "_index" : "test"} }{ "doc" : {"field2" : "value2"} }索引操作(Index)效果:如果文档 ID=1 已存在,则替换它;如果不存在,则创建新文档
删除操作(Delete)效果: 删除 ID=2 的文档(如果存在)
创建操作(Create)效果:创建 ID=3 的新文档,如果该 ID 已存在,则操作会失败(报错)
更新操作(Update)效果:对 ID=1 的文档进行部分更新
这里的test是目标索引库
_index:指定索引库名_id指定要操作的文档id
示例,批量新增:
POST /_bulk{"index": {"_index":"heima", "_id": "3"}}{"info": "黑马程序员C++讲师", "email": "ww@itcast.cn", "name":{"firstName": "五", "lastName":"王"}}{"index": {"_index":"heima", "_id": "4"}}{"info": "黑马程序员前端讲师", "email": "zhangsan@itcast.cn", "name":{"firstName": "三", "lastName":"张"}}WARNING注意这里的新增信息,不能换行
批量删除:
POST /_bulk{"delete":{"_index":"heima", "_id": "3"}}{"delete":{"_index":"heima", "_id": "4"}}RestClient
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。
官方文档地址: https://www.elastic.co/guide/en/elasticsearch/client/index.html
由于ES目前最新版本是8.8,提供了全新版本的客户端,老版本的客户端已经被标记为过时。而我们采用的是7.12版本
注意
7.15以后的新版本都是基于lambda表达式的写法了;项目中用新版本的注意下;初始化RestClient
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
1)在item-service模块中引入es的RestHighLevelClient依赖:
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId></dependency>2)因为SpringBoot默认的ES版本是7.17.10,所以我们需要覆盖默认的ES版本:
在父工程hmall的pom.xml中覆盖
<properties> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> <elasticsearch.version>7.12.1</elasticsearch.version> </properties>3)初始化RestHighLevelClient:
初始化的代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.150.101:9200")));在该服务下建一个测试,测试一下
public class ElasticSearchTest {
private RestHighLevelClient restHighLevelClient;
@Test void testConnection() { System.out.println(restHighLevelClient); }
@BeforeEach void setUp() { restHighLevelClient = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.146.131:9200") )); }
@AfterEach void tearDown() throws IOException { if (restHighLevelClient != null) { restHighLevelClient.close(); } }}假如是集群部署,可以多节点配置
restHighLevelClient = new RestHighLevelClient( RestClient.builder( new HttpHost("192.168.146.131", 9200, "http"), new HttpHost("192.168.146.132", 9200, "http") ));@BeforeEach初始化方法, 表示该方法在每个测试方法执行前都会运行@AfterEach表示该方法在每个测试方法执行后都会运行
商品的Mapping映射
由于要实现对商品搜索,所以我们需要将商品添加到Elasticsearch中,不过需要根据搜索业务的需求来设定索引库结构,而不是一股脑的把MySQL数据写入Elasticsearch.
实现搜索功能需要的字段包括三大部分:
- 搜索过滤字段
- 分类
- 品牌
- 价格
- 排序字段
- 默认:按照更新时间降序排序
- 销量
- 价格
- 展示字段
- 商品id:用于点击后跳转
- 图片地址
- 是否是广告推广商品
- 名称
- 价格
- 评价数量
- 销量
也就是页面上展示的这些,都要存到es中
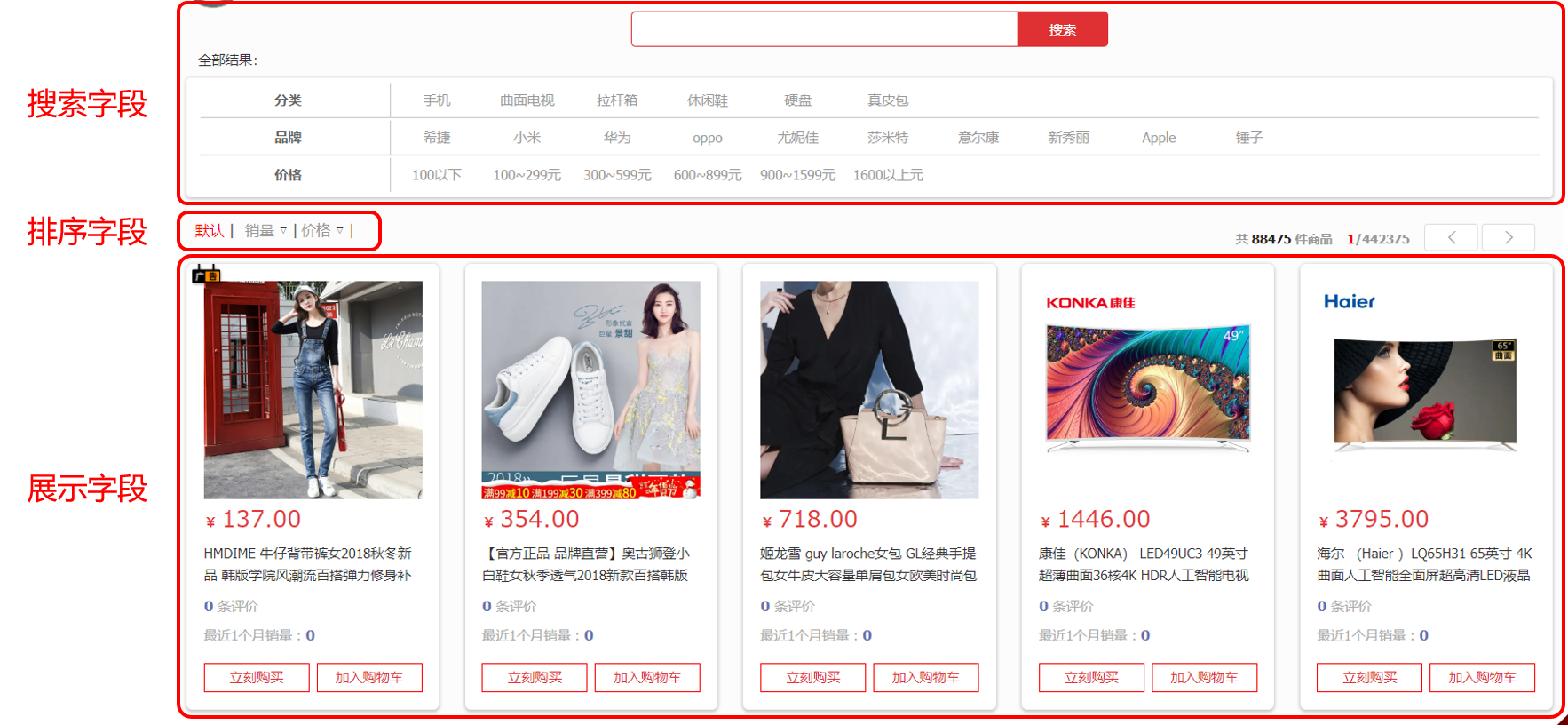
结合数据库表结构,以上字段对应的mapping映射属性如下:
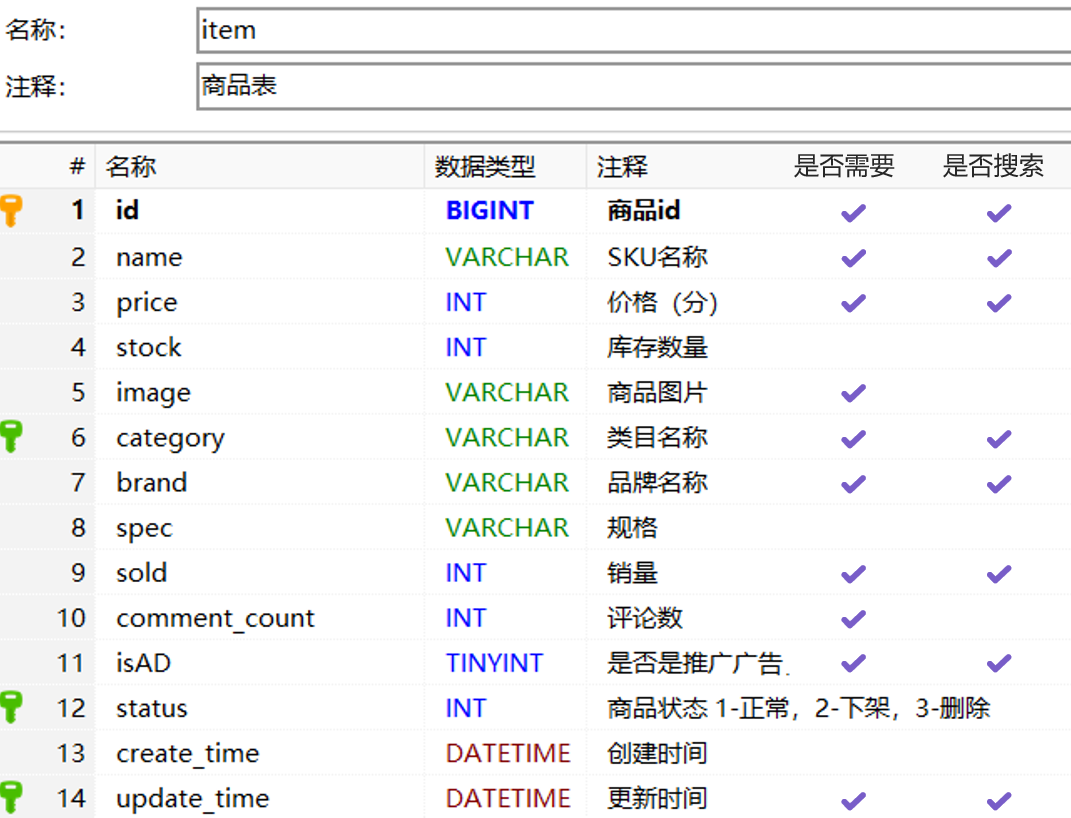
因此,最终我们的索引库文档结构应该是这样:
PUT /items{ "mappings": { "properties": { "id": { "type": "keyword" }, "name":{ "type": "text", "analyzer": "ik_max_word" }, "price":{ "type": "integer" }, "image":{ "type": "keyword", "index": false }, "category":{ "type": "keyword" }, "brand":{ "type": "keyword" }, "sold":{ "type": "integer" }, "commentCount":{ "type": "integer", "index": false }, "isAD":{ "type": "boolean" }, "updateTime":{ "type": "date" } } }}索引库操作
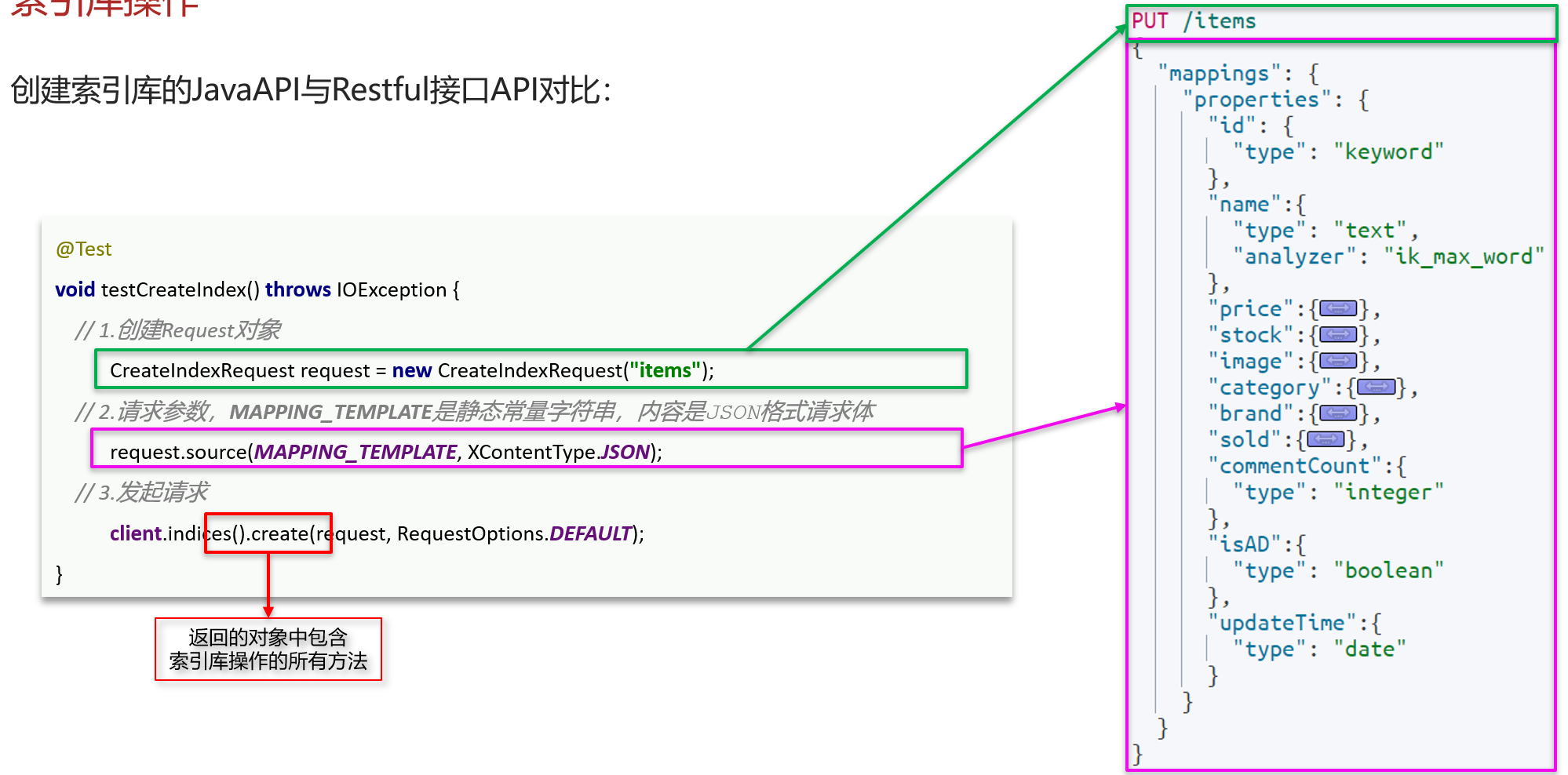 代码分为三步:
代码分为三步:
- 1)创建Request对象。
- 因为是创建索引库的操作,因此Request是CreateIndexRequest。
- 2)添加请求参数
- 其实就是Json格式的Mapping映射参数。因为json字符串很长,这里是定义了静态字符串常量MAPPING_TEMPLATE,让代码看起来更加优雅。
- 3)发送请求
- client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。例如创建索引、删除索引、判断索引是否存在等
创建索引库及mapping映射:
public class ElasticSearchTest {
private RestHighLevelClient restHighLevelClient;
@Test void testConnection() { System.out.println(restHighLevelClient); }
@BeforeEach void setUp() { restHighLevelClient = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.146.131:9200") )); }
@AfterEach void tearDown() throws IOException { if (restHighLevelClient != null) { restHighLevelClient.close(); } }
@Test void testCreateIndex() throws IOException { // 1.准备request对象 CreateIndexRequest request = new CreateIndexRequest("items"); // 2.准备请求参数 request.source(MAPPING_TEMPLATE, XContentType.JSON); // 3.发送请求 restHighLevelClient.indices().create(request, RequestOptions.DEFAULT); }
private final static String MAPPING_TEMPLATE = "{\n" + " \"mappings\": {\n" + " \"properties\": {\n" + " \"id\": {\n" + " \"type\": \"keyword\"\n" + " },\n" + " \"name\":{\n" + " \"type\": \"text\",\n" + " \"analyzer\": \"ik_max_word\"\n" + " },\n" + " \"price\":{\n" + " \"type\": \"integer\"\n" + " },\n" + " \"image\":{\n" + " \"type\": \"keyword\",\n" + " \"index\": false\n" + " },\n" + " \"category\":{\n" + " \"type\": \"keyword\"\n" + " },\n" + " \"brand\":{\n" + " \"type\": \"keyword\"\n" + " },\n" + " \"sold\":{\n" + " \"type\": \"integer\"\n" + " },\n" + " \"commentCount\":{\n" + " \"type\": \"integer\",\n" + " \"index\": false\n" + " },\n" + " \"isAD\":{\n" + " \"type\": \"boolean\"\n" + " },\n" + " \"updateTime\":{\n" + " \"type\": \"date\"\n" + " }\n" + " }\n" + " }\n" + "}";}查询索引库
@Test void testGetIndex() throws IOException { // 1.准备request对象 GetIndexRequest request = new GetIndexRequest("items"); // 3.发送请求 GetIndexResponse getIndexResponse = restHighLevelClient.indices().get(request, RequestOptions.DEFAULT); System.out.println(getIndexResponse); }检查是否存在:
@Test void testGetIndex() throws IOException { // 1.准备request对象 GetIndexRequest request = new GetIndexRequest("items"); // 3.发送请求 boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT); System.out.println(exists); }- 1)创建Request对象。这次是
GetIndexRequest对象 - 2)准备参数。这里是无参,直接省略
- 3)发送请求。改用exists方法
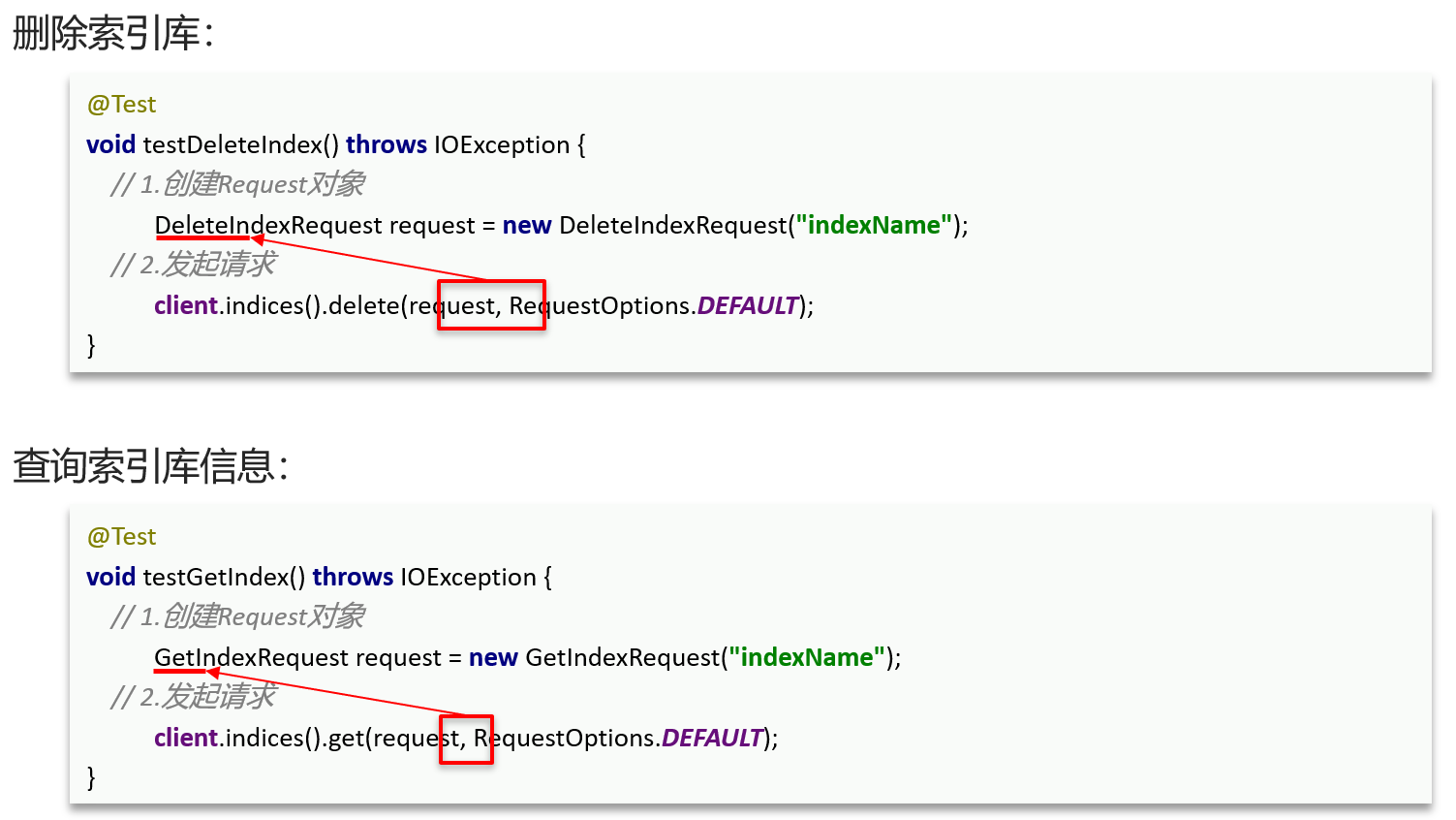
删除索引库
@Test void testDeleteIndex() throws IOException { // 1.准备request对象 DeleteIndexRequest request = new DeleteIndexRequest("items"); // 3.发送请求 restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT); }注意体现在Request对象上。流程如下:
- 1)创建Request对象。这次是
DeleteIndexRequest对象 - 2)准备参数。这里是无参,因此省略
- 3)发送请求。改用delete方法
总结
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化
RestHighLevelClient - 创建XxxIndexRequest。XXX是
Create、Get、Delete - 准备请求参数( Create时需要,其它是无参,可以省略)
- 发送请求。调用
RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
RestClient操作文档
索引库准备好以后,就可以操作文档了。为了与索引库操作分离,我们再次创建一个测试类
新增文档
新增文档的请求语法如下:
POST /{索引库名}/_doc/1{ "name": "Jack", "age": 21}对应的JavaAPI如下:

索引库结构与数据库结构还存在一些差异,因此我们要定义一个索引库结构对应的实体。
在item-service模块的com.hmall.item.domain.po包中定义一个新的:ItemDoc
package com.hmall.item.domain.po;
import io.swagger.annotations.ApiModel;import io.swagger.annotations.ApiModelProperty;import lombok.Data;
import java.time.LocalDateTime;
@Data@ApiModel(description = "索引库实体")public class ItemDoc{
@ApiModelProperty("商品id") private String id;
@ApiModelProperty("商品名称") private String name;
@ApiModelProperty("价格(分)") private Integer price;
@ApiModelProperty("商品图片") private String image;
@ApiModelProperty("类目名称") private String category;
@ApiModelProperty("品牌名称") private String brand;
@ApiModelProperty("销量") private Integer sold;
@ApiModelProperty("评论数") private Integer commentCount;
@ApiModelProperty("是否是推广广告,true/false") private Boolean isAD;
@ApiModelProperty("更新时间") private LocalDateTime updateTime;}测试类代码如下:
@SpringBootTest(properties = "spring.profiles.active=local")public class ElasticSearchDocumentTest {
private RestHighLevelClient restHighLevelClient;
@Autowired private IItemService itemService;
@BeforeEach void setUp() { restHighLevelClient = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.146.131:9200") )); }
@AfterEach void tearDown() throws IOException { if (restHighLevelClient != null) { restHighLevelClient.close(); } }
@Test void testIndexDoc() throws IOException { // 0.准备文档数据 Item item = itemService.getById(546872L); // 把数据库数据转为文档数据 ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class); // 1. 准备request IndexRequest request = new IndexRequest("items").id(item.getId().toString()); // 2.准备请求参数 request.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON); // 3.发送请求 restHighLevelClient.index(request, RequestOptions.DEFAULT); }}可以看到与索引库操作的API非常类似,同样是三步走:
- 1)创建Request对象,这里是
IndexRequest,因为添加文档就是创建倒排索引的过程 - 2)准备请求参数,本例中就是Json文档
- 3)发送请求
变化的地方在于,这里直接使用client.xxx()的API,不再需要client.indices()了。
new IndexRequest这里的Index会先判断这个id是否存在,如果存在就会update,如果不存在就会create,并且这个id是可以不指定的,会自动创建
@SpringBootTest,这是 Spring Boot 测试的核心注解,它会:启动完整的 Spring 应用上下文(包括所有自动配置的 bean)、模拟真实的应用程序启动过程、 提供测试所需的完整环境(包括配置属性、数据库连接等)、支持依赖注入(可以使用 @Autowired 注入任何 Spring 管理的 bean)
properties = "spring.profiles.active=local" 参数,这会加载application-local.yml 配置文件,即使应用默认配置中设置了其他 profile,测试时也会强制使用 “local” profile
BeanUtil.copyProperties(hutool) 根据一个已有的 Java Bean 对象(item),创建一个新的 ItemDoc 类型的对象,并将属性名相同的字段值复制过去。
查询文档
GET /{索引库名}/_doc/{id}
@Test void testGetDoc() throws IOException { // 1. 准备request GetRequest request = new GetRequest("items", "546872"); // 2.发送请求 GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT); // 3.解析结果 String json = response.getSourceAsString(); ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class); System.out.println("doc = " + doc); }- 1)准备Request对象。这次是查询,所以是GetRequest
- 2)发送请求,得到结果。因为是查询,这里调用client.get()方法
- 3)解析结果,就是对JSON做反序列化
删除文档
删除的请求语句如下:
DELETE /hotel/_doc/{id}对应API:
@Test void testDeleteDoc() throws IOException { // 1. 准备request DeleteRequest request = new DeleteRequest("items", "546872"); // 2.发送请求 restHighLevelClient.delete(request, RequestOptions.DEFAULT); }修改文档
修改文档数据有两种方式:
- 方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档。与新增的JavaAPI一致。
- 方式二:局部更新。只更新指定部分字段。
全量更新
全量更新和新增是一样的操作API,如果这个id的数据存在则修改,不存在则添加
@Test void testIndexDoc() throws IOException { // 0.准备文档数据 Item item = itemService.getById(546872L); // 把数据库数据转为文档数据 ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class); itemDoc.setPrice(9999999); // 1. 准备request IndexRequest request = new IndexRequest("items").id(item.getId().toString()); // 2.准备请求参数 request.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON); // 3.发送请求 IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT); System.out.println("response = " + response); }局部更新
POST /{索引库名}/_update/{id}{ "doc": { "字段名": "字段值", "字段名": "字段值" }}
@Test void testUpdateDoc() throws IOException { // 1. 准备request UpdateRequest request = new UpdateRequest("items", "546872"); // 2. 准备请求参数 request.doc( // 这里也可以用Map "price", "666", "sold", "36" ); // 3.发送请求 restHighLevelClient.update(request, RequestOptions.DEFAULT); }文档操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxRequest。XXX是Index、Get、Update、Delete
- 准备参数(Index和Update时需要)
- 发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete
- 解析结果(Get时需要)
批处理
批处理与前面讲的文档的CRUD步骤基本一致:
- 创建
Request,但这次用的是BulkRequest - 准备请求参数
- 发送请求,这次要用到
client.bulk()方法
BulkRequest本身其实并没有请求参数,其本质就是将多个普通的CRUD请求组合在一起发送。例如:
- 批量新增文档,就是给每个文档创建一个
IndexRequest请求,然后封装到BulkRequest中,一起发出。 - 批量删除,就是创建N个
DeleteRequest请求,然后封装到BulkRequest,一起发出
因此BulkRequest中提供了add方法,用以添加其它CRUD的请求:
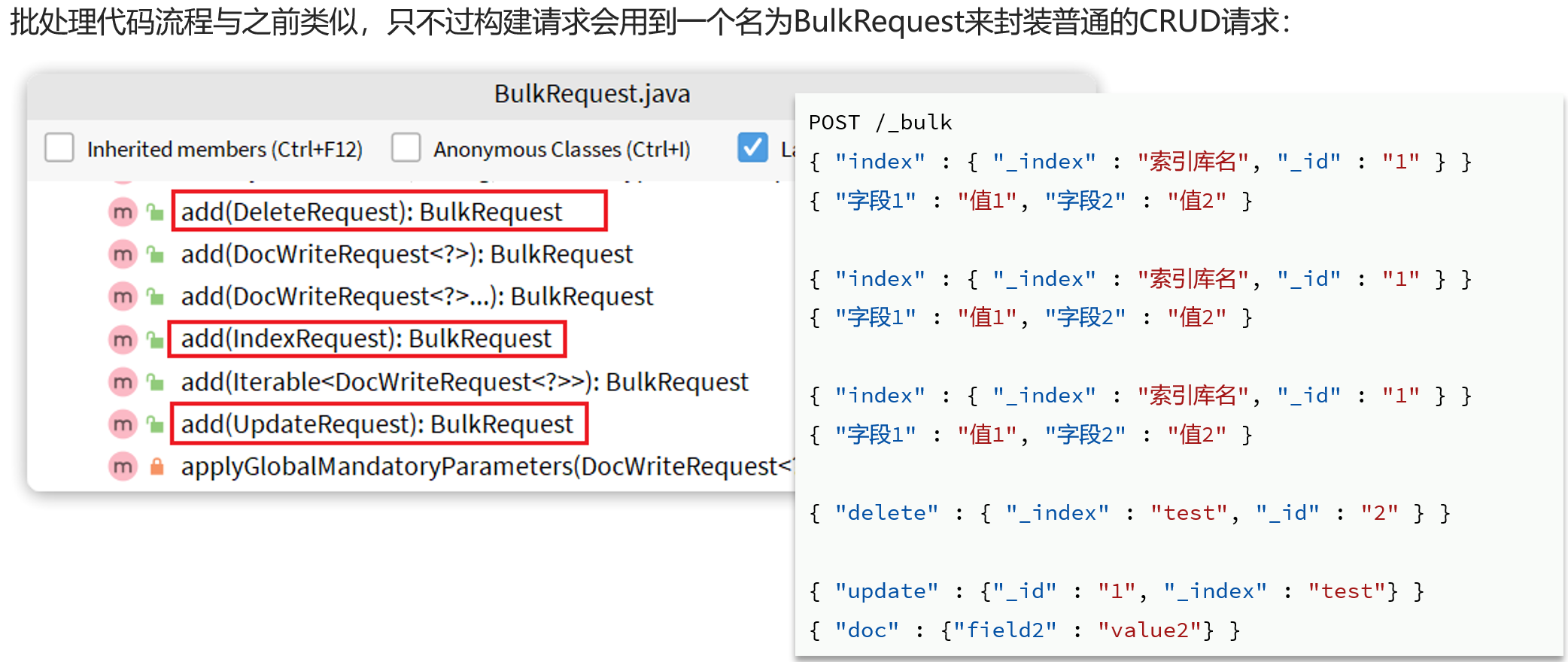
可以看到,能添加的请求有:
IndexRequest,也就是新增UpdateRequest,也就是修改DeleteRequest,也就是删除
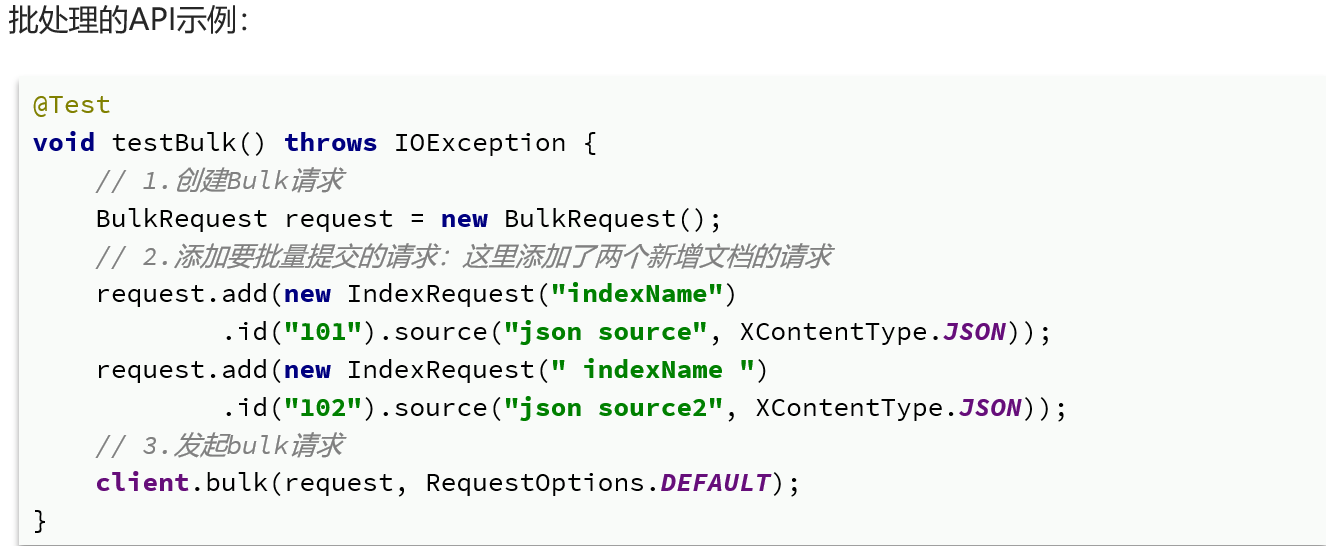
当我们要导入商品数据时,由于商品数量达到数十万,因此不可能一次性全部导入。建议采用循环遍历方式,每次导入1000条左右的数据。
@Test void testBulkDoc() throws IOException { int pageNo = 1, pageSize = 500; // 准备文档数据 while (true) { Page<Item> page = itemService.lambdaQuery() .eq(Item::getStatus, 1) .page(Page.of(pageNo, pageSize)); List<Item> records = page.getRecords(); if (records == null || records.isEmpty()) { return; }
// 1. 准备request BulkRequest request = new BulkRequest(); // 2. 准备请求参数 for (Item item : records) { request.add(new IndexRequest("items") .id(item.getId().toString()) .source(JSONUtil.toJsonStr(BeanUtil.copyProperties(item, ItemDoc.class)), XContentType.JSON)); } // 3.发送请求 restHighLevelClient.bulk(request, RequestOptions.DEFAULT); pageNo++; } }查看索引库有多少条文档数据:
GET items/_countDSL查询
我们来研究下elasticsearch的数据搜索功能。Elasticsearch提供了基于JSON的DSL(Domain Specific Language)语句来定义查询条件,其JavaAPI就是在组织DSL条件。
因此,我们先学习DSL的查询语法,然后再基于DSL来对照学习JavaAPI,就会事半功倍。
Elasticsearch的查询可以分为两大类:
- 叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
- 复合查询(Compound query clauses):以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
在查询以后,还可以对查询的结果做处理,包括:
- 排序:按照1个或多个字段值做排序
- 分页:根据from和size做分页,类似MySQL
- 高亮:对搜索结果中的关键字添加特殊样式,使其更加醒目
- 聚合:对搜索结果做数据统计以形成报表
快速入门
我们依然在Kibana的DevTools中学习查询的DSL语法。首先来看查询的语法结构:
GET /{索引库名}/_search{ "query": { "查询类型": { // .. 查询条件 } }}说明:
GET /{索引库名}/_search:其中的_search是固定路径,不能修改
例如,我们以最简单的无条件查询为例,无条件查询的类型是:match_all,因此其查询语句如下:
GET /items/_search{ "query": { "match_all": {
} }}由于match_all无条件,所以条件位置不写即可。
执行结果如下:
 你会发现虽然是
你会发现虽然是match_all,但是响应结果中并不会包含索引库中的所有文档,而是仅有10条。这是因为处于安全考虑,elasticsearch设置了默认的查询页数。
叶子查询
叶子查询还可以进一步细分,常见的有:
- 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去词条列表中匹配。例如:
match_querymulti_match_query
- 精确查询:不对用户输入内容分词,直接精确匹配,一般是查找keyword、数值、日期、布尔等类型。例如:
idsrangeterm
- 地理(geo)查询:用于搜索地理位置,搜索方式很多。例如:
geo_distancegeo_bounding_box
全文检索查询
全文检索的种类也很多,详情可以参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/full-text-queries.html
以全文检索中的match为例,语法如下:
GET /{索引库名}/_search{ "query": { "match": { "字段名": "搜索条件" } }}示例
GET items/_search{ "query": { "match": { "name": "脱脂牛奶" } }}响应结果:

::: tip 基础相关性评分(_score): 按照匹配度打分排名,相关度评分是基于BM25(Best Matching 25)算法来计算的,这是一种改进的TF-IDF(Term Frequency-Inverse Document Frequency)算法。 :::
与match类似的还有multi_match,区别在于可以同时对多个字段搜索,条件是或的关系,满足 (字段1 有 搜索条件) || (字段2 有 搜索条件) 就会被搜索出来,语法示例:
GET /{索引库名}/_search{ "query": { "multi_match": { "query": "搜索条件", "fields": ["字段1", "字段2"] } }}query:要搜索的文本内容;fields:要在哪些字段中搜索该内容- 在
multi_match查询的fields参数中,字段之间的关系是 “或”(OR)关系,而不是”与”(AND)关系。
示例:
GET items/_search{ "query": {"multi_match": { "query": "小米", "fields": ["name","brand"] }}}精确查询
精确查询,英文是Term-level query,顾名思义,词条级别的查询。也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配。
因此推荐查找keyword、数值、日期、boolean类型的字段。例如id、price、城市、地名、人名等作为一个整体才有含义的字段。
详情可以查看官方文档:es文档
以term查询为例,其语法如下:
GET /{索引库名}/_search{ "query": { "term": { "字段名": { "value": "搜索条件" } } }}示例:
GET items/_search{ "query": { "term": { "brand": { "value": "德亚" } } }}WARNING当你输入的搜索条件不是词条,而是短语时,由于不做分词,你反而搜索不到!
再来看下range查询,语法如下:
GET /{索引库名}/_search{ "query": { "range": { "字段名": { "gte": {最小值}, "lte": {最大值} } } }}range是范围查询,对于范围筛选的关键字有:
- gte:大于等于
- gt:大于
- lte:小于等于
- lt:小于
示例:
GET items/_search{ "query": { "range": { "price": { "gte": 10000, "lte": 20000 } } }}根据ids查询
GET /items/_search{ "query": { "ids": { "values": [ "613358", "584392" ] } }}WARNING需要注意的是精确搜索是没有得分的,没有分数排名,因为是精确搜索,大家分数都一样
总结
match和multi_match的区别是什么?
match:根据一个字段查询multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
精确查询常见的有哪些?
term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段range查询:根据数值范围查询,可以是数值、日期的范围根据ids查询
复合查询
复合查询大致可以分为两类:
- 第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
bool
- 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
function_score
dis_max
其它复合查询及相关语法可以参考官方文档: es文档
bool查询
bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool查询支持的逻辑运算有:
must:必须匹配每个子查询,类似“与”should:选择性匹配子查询,类似“或”must_not:必须不匹配,不参与算分,类似“非”filter:必须匹配,不参与算分
bool查询的语法如下:
GET /items/_search{ "query": { "bool": { "must": [ {"match": {"name": "手机"}} ], "should": [ {"term": {"brand": { "value": "vivo" }}}, {"term": {"brand": { "value": "小米" }}} ], "must_not": [ {"range": {"price": {"gte": 2500}}} ], "filter": [ {"range": {"price": {"lte": 1000}}} ] } }}示例:
- 需求:我们要搜索”智能手机”,但品牌必须是华为,价格必须是900~1599
出于性能考虑,与搜索关键字无关的查询尽量采用must_not或filter逻辑运算,避免参与相关性算分。
例如商城的搜索页面:
 其中输入框的搜索条件肯定要参与相关性算分,可以采用
其中输入框的搜索条件肯定要参与相关性算分,可以采用must。但是价格范围过滤、品牌过滤、分类过滤等尽量采用filter,不要参与相关性算分。
GET /items/_search{ "query": { "bool": { "must": [ { "match": { "name": "智能手机" } } ], "filter": [ { "term": { "brand": "华为" } }, { "range": { "price": { "gte": 90000, "lte": 159900 } } } ] } }}响应:
一般来说用户通过关键字进行搜索,我们是需要进行算分的(_score),而通过条件进行筛选的我们是不需要算分的,比如价格区间筛选等,es即使这样;
而且参与算分的越多,那么性能肯定也是会下降的,效率会变低;
排序和分页
语法说明:
GET /indexName/_search{ "query": { "match_all": {} }, "sort": [ { "排序字段": { "order": "排序方式asc和desc" } } ]}sort关键字:进行排序操作,sort的值是一个数组,所以可以指定多个排序的字段
- 需求:搜索商品,按照销量排序,销量一样则按照价格升序
GET /items/_search{ "query": { "match_all": {} }, "sort": [ { "sold": "desc" }, { "price": "asc" } ]}分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
类似于mysql中的
limit ?, ?
官方文档如下:文档
语法如下:
GET /items/_search{ "query": { "match_all": {} }, "from": 0, // 分页开始的位置,默认为0 "size": 10, // 每页文档数量,默认10 "sort": [ { "price": { "order": "desc" } } ]}- 需求:搜索商品,查询出销量排名前10的商品,销量一样时按照价格升序
GET /items/_search{ "query": { "match_all": {} }, "sort": [ { "sold": "desc" }, { "price": "asc" } ], "from": 0, "size": 10}深度分页
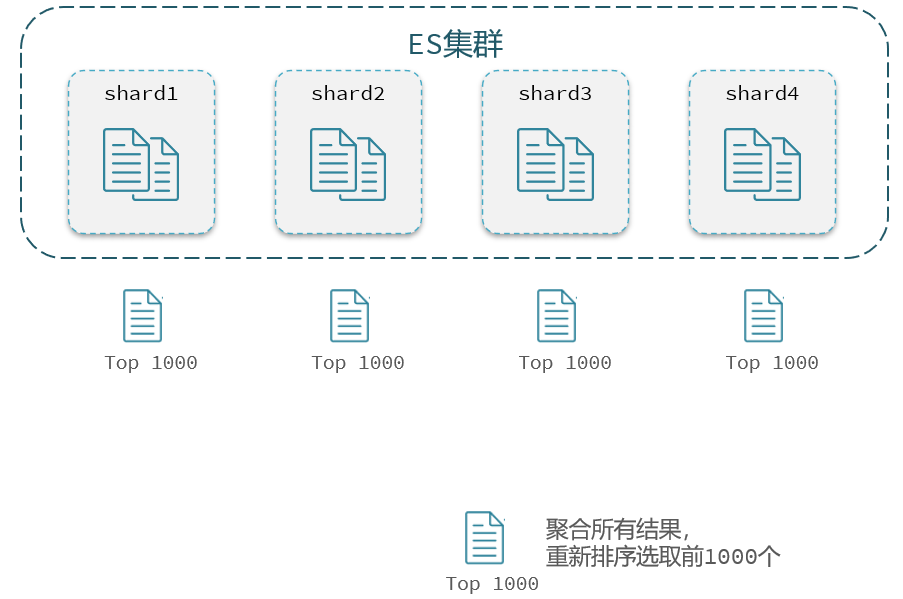
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
比如一个索引库中有100000条数据,分别存储到4个分片,每个分片25000条数据。现在每页查询10条,查询第99页。那么分页查询的条件如下:
GET /items/_search{ "from": 990, // 从第990条开始查询 "size": 10, // 每页查询10条 "sort": [ { "price": "asc" } ]}从语句来分析,要查询第990~1000名的数据。
从实现思路来分析,肯定是将所有数据排序,找出前1000名,截取其中的990~1000的部分。但问题来了,我们如何才能找到所有数据中的前1000名呢?
要知道每一片的数据都不一样,第1片上的第9001000,在另1个节点上并不一定依然是9001000名。所以我们只能在每一个分片上都找出排名前1000的数据,然后汇总到一起,重新排序,才能找出整个索引库中真正的前1000名,此时截取990~1000的数据即可。
如图:
试想一下,假如我们现在要查询的是第999页数据呢,是不是要找第9990~10000的数据,那岂不是需要把每个分片中的前10000名数据都查询出来,汇总在一起,在内存中排序?如果查询的分页深度更深呢,需要一次检索的数据岂不是更多?
由此可知,当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力。
因此elasticsearch会禁止from+size 超过10000的请求。
针对深度分页,elasticsearch提供了两种解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。scroll:原理将排序后的文档id形成快照,保存下来,基于快照做分页。官方已经不推荐使用。
search after模式:
优点:没有查询上限,支持深度分页
缺点:只能向后逐页查询,不能随机翻页
场景:数据迁移、手机滚动查询
详情见文档:文档
::: tip
search after的原理就是,当翻到某一页时,会记住当前的最后一页,那么下次再翻页时,就会把上次记住的那一页作为查询条件继续翻页,条件是大于上次记住的那一页,size限制xxx页数,这样就实现了每次翻页都是第一页
假设你在看一本书,你已经翻到某一页(例如第10页),然后你想继续看第11页。search_after就像是“给你上一页的最后一行文字”,让你知道接下来你应该从哪里开始读,而不是从头开始翻书(就像from那样跳过很多页) :::
WARNING总结:
大多数情况下,我们采用普通分页就可以了。查看百度、京东等网站,会发现其分页都有限制。例如百度最多支持77页,每页不足20条。京东最多100页,每页最多60条。 因此,一般我们采用限制分页深度的方式即可,无需实现深度分页。
高亮
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示:
观察页面源码,你会发现两件事情:
- 高亮词条都被加了
<em>标签 <em>标签都添加了红色样式
css样式肯定是前端实现页面的时候写好的,但是前端编写页面的时候是不知道页面要展示什么数据的,不可能给数据加标签。而服务端实现搜索功能,要是有elasticsearch做分词搜索,是知道哪些词条需要高亮的。
因此词条的高亮标签肯定是由服务端提供数据的时候已经加上的。
因此实现高亮的思路就是:
- 用户输入搜索关键字搜索数据
- 服务端根据搜索关键字到elasticsearch搜索,并给搜索结果中的关键字词条添加html标签
- 前端提前给约定好的html标签添加CSS样式
实现高亮
事实上elasticsearch已经提供了给搜索关键字加标签的语法,无需我们自己编码。
基本语法如下:
GET /{索引库名}/_search{ "query": { "match": { "搜索字段": "搜索关键字" } }, "highlight": { "fields": { "高亮字段名称": { "pre_tags": "<em>", "post_tags": "</em>" } } }}示例:
GET /items/_search{ "query": { "match": { "name": "脱脂牛奶" } }, "highlight": { "fields": { "name": { "pre_tags": "<em>", "post_tags": "</em>" } } }}部分响应结果:
{ "took" : 547, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1149, "relation" : "eq" }, "max_score" : 16.198345, "hits" : [ { "_index" : "items", "_type" : "_doc", "_id" : "33449279171", "_score" : 16.198345, "_source" : { "id" : "33449279171", "name" : "意大利 进口牛奶 葛兰纳诺脱脂纯牛奶 成人牛奶 进口脱脂纯牛奶1Lx6盒", "price" : 3500, "image" : "https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/25045/9/2656/164517/5c20699dE9b7f4c9c/1a05e9bdd2c5d59e.jpg!q70.jpg.webp", "category" : "牛奶", "brand" : "葛兰纳诺", "sold" : 0, "commentCount" : 0, "isAD" : false, "updateTime" : 1556640000000 }, "highlight" : { "name" : [ "意大利 进口<em>牛奶</em> 葛兰纳诺<em>脱脂</em>纯<em>牛奶</em> 成人<em>牛奶</em> 进口<em>脱脂</em>纯<em>牛奶</em>1Lx6盒" ] } }, ] }WARNING注意:
- 搜索必须有查询条件,而且是全文检索类型的查询条件,例如match
- 参与高亮的字段必须是text类型的字段
- 默认情况下参与高亮的字段要与搜索字段一致,除非添加:required_field_match=false
总结
查询的DSL是一个大的JSON对象,包含下列属性:
query:查询条件from和size:分页条件sort:排序条件highlight:高亮条件
搜索的完整语法:
GET /items/_search{ "query": { "match": { "name": "华为" } }, "from": 0, // 分页开始的位置 "size": 20, // 期望获取的文档总数 "sort": [ { "price": "asc" }, // 普通排序 ], "highlight": { "fields": { // 高亮字段 "name": { "pre_tags": "<em>", // 高亮字段的前置标签 "post_tags": "</em>" // 高亮字段的后置标签 } } }}JavaRestClient查询
文档的查询依然使用昨天学习的 RestHighLevelClient对象,查询的基本步骤如下:
- 1)创建request对象,这次是搜索,所以是SearchRequest
- 2)准备请求参数,也就是查询DSL对应的JSON参数
- 3)发起请求
- 4)解析响应,响应结果相对复杂,需要逐层解析
快速入门
由于Elasticsearch对外暴露的接口都是Restful风格的接口,因此JavaAPI调用就是在发送Http请求。而我们核心要做的就是利用利用Java代码组织请求参数,解析响应结果。
发送请求
首先以match_all查询为例,其DSL和JavaAPI的对比如图:
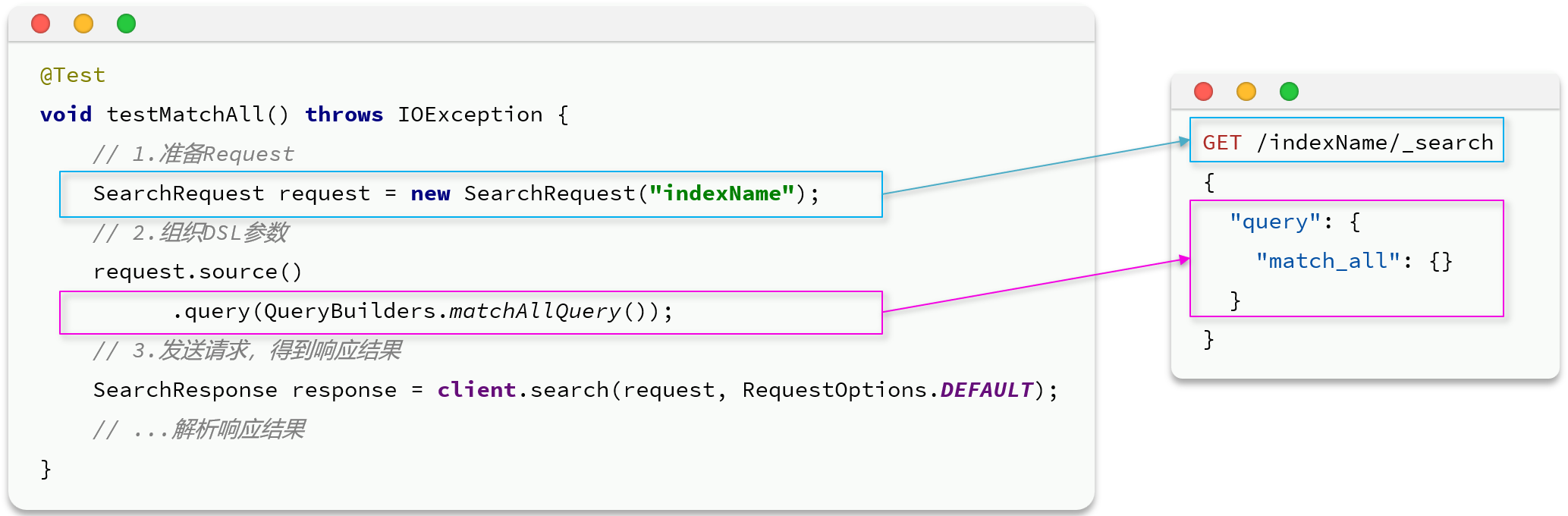
代码解读:
- 第一步,创建
SearchRequest对象,指定索引库名 - 第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等 - query():代表查询条件,利用
QueryBuilders.matchAllQuery()构建一个match_all查询的DSL - 第三步,利用client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),它构建的就是DSL中的完整JSON参数。其中包含了query、sort、from、size、highlight等所有功能
另一个是QueryBuilders,其中包含了我们学习过的各种叶子查询、复合查询等
解析响应的结果
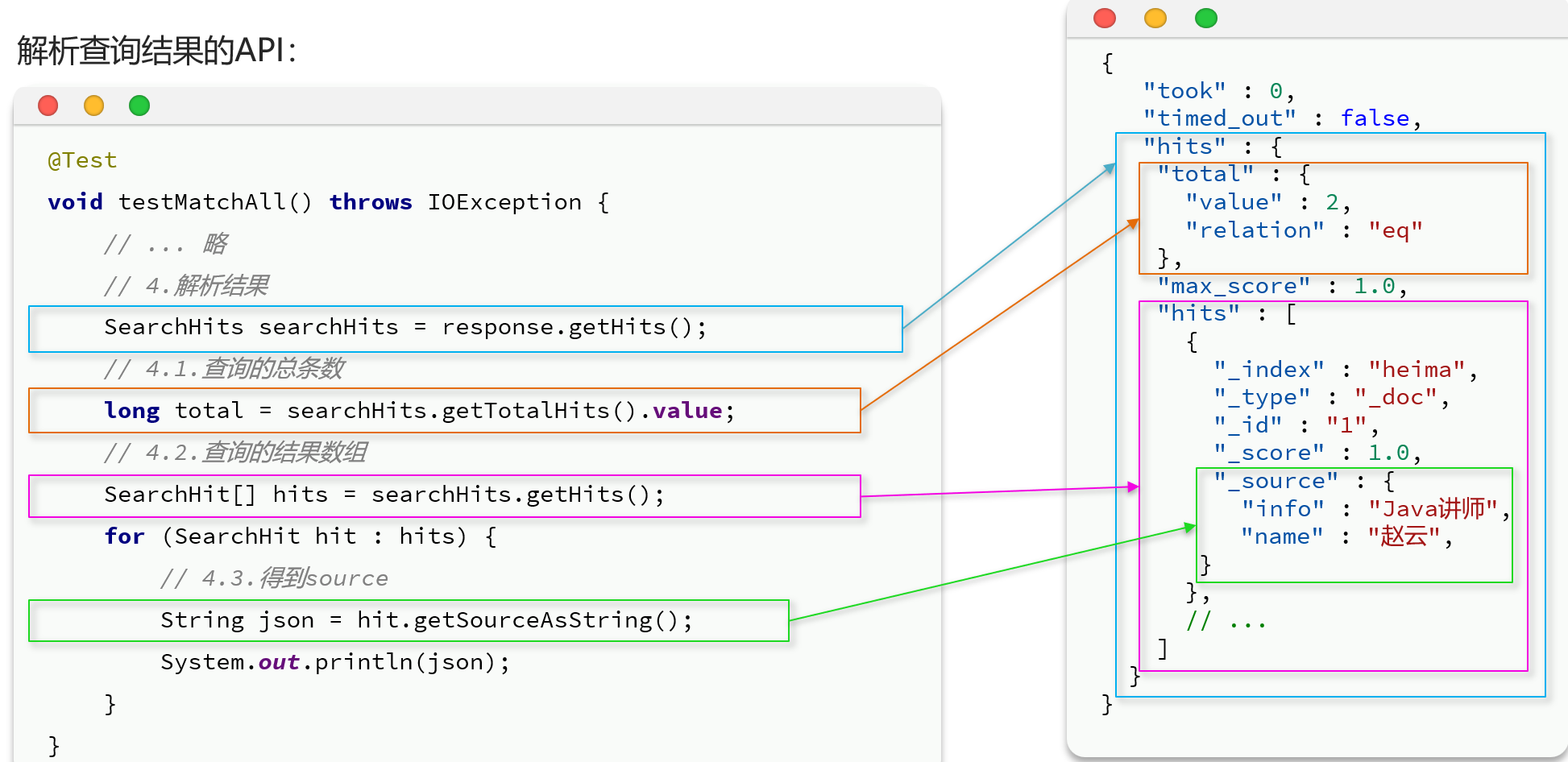
代码解读:
elasticsearch返回的结果是一个JSON字符串,结构包含:
hits:命中的结果total:总条数,其中的value是具体的总条数值max_score:所有结果中得分最高的文档的相关性算分hits:搜索结果的文档数组,其中的每个文档都是一个json对象_source:文档中的原始数据,也是json对象
因此,我们解析响应结果,就是逐层解析JSON字符串,流程如下:
SearchHits:通过response.getHits()获取,就是JSON中的最外层的hits,代表命中的结果SearchHits.getTotalHits().value:获取总条数信息SearchHits.getHits():获取SearchHit数组,也就是文档数组SearchHit.getSourceAsString():获取文档结果中的_source,也就是原始的json文档数据
示例代码:
@SpringBootTest(properties = "spring.profiles.active=local")public class ElasticeSearchTest {
private RestHighLevelClient restHighLevelClient;
@Autowired private IItemService itemService;
@BeforeEach void setUp() { restHighLevelClient = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.146.131:9200") )); }
@AfterEach void tearDown() throws IOException { if (restHighLevelClient != null) { restHighLevelClient.close(); } }
@Test void testSearch() throws IOException { // 1. 创建request对象 SearchRequest request = new SearchRequest("items"); // 2. 配置requset参数 request.source().query(QueryBuilders.matchAllQuery()); // 3.发送请求 SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT); // 4. 解析结果 SearchHits searchHits = response.getHits(); // 总条数 long total = searchHits.getTotalHits().value; System.out.println("total = " + total); // 命中的数据 SearchHit[] hits = searchHits.getHits(); for (SearchHit hit : hits) { String json = hit.getSourceAsString(); ItemDoc itemDoc = JSONUtil.toBean(json, ItemDoc.class); System.out.println("itemDoc = " + itemDoc); } }}总结
文档搜索的基本步骤是:
- 创建
SearchRequest对象 - 准备
request.source(),也就是DSL。QueryBuilders来构建查询条件- 传入
request.source()的query()方法
- 发送请求,得到结果
- 解析结果(参考JSON结果,从外到内,逐层解析)
叶子查询
全文检索的查询条件构造API如下:

精确查询的查询条件构造API如下:

所有的查询条件都是由QueryBuilders来构建的,叶子查询也不例外。因此整套代码中变化的部分仅仅是query条件构造的方式,其它不动。
例如match查询:
@Testvoid testMatch() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶")); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response);}再比如multi_match查询:
@Testvoid testMultiMatch() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.multiMatchQuery("脱脂牛奶", "name", "category")); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response);}还有range查询:
@Testvoid testRange() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.rangeQuery("price").gte(10000).lte(30000)); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response);}还有term查询:
@Testvoid testTerm() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.termQuery("brand", "华为")); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response);}复合查询
布尔查询的查询条件构造API如下:

- 需求:利用JavaRestClient实现搜索功能,条件如下:
搜索关键字为脱脂牛奶
品牌必须为德亚
价格必须低于300
@SpringBootTest(properties = "spring.profiles.active=local")public class ElasticeSearchTest {
private RestHighLevelClient restHighLevelClient;
@Autowired private IItemService itemService;
@BeforeEach void setUp() { restHighLevelClient = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.146.131:9200") )); }
@AfterEach void tearDown() throws IOException { if (restHighLevelClient != null) { restHighLevelClient.close(); } }
@Test void testSearchMatchAll() throws IOException { // 1. 创建request对象 SearchRequest request = new SearchRequest("items"); // 2. 配置requset参数 request.source().query(QueryBuilders.matchAllQuery()); // 3.发送请求 SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT); // 4. 解析结果 parseResponseResult(response); }
@Test void testSearch() throws IOException { // 1. 创建request对象 SearchRequest request = new SearchRequest("items");
// 2. 配置requset参数 request.source().query( QueryBuilders.boolQuery() .must(QueryBuilders.matchQuery("name", "脱脂牛奶")) .filter(QueryBuilders.termQuery("brand", "德亚")) .filter(QueryBuilders.rangeQuery("price").lt("30000")) ); // 3.发送请求 SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT); // 4. 解析结果 parseResponseResult(response); }
private static void parseResponseResult(SearchResponse response) { SearchHits searchHits = response.getHits(); // 总条数 long total = searchHits.getTotalHits().value; System.out.println("total = " + total); // 命中的数据 SearchHit[] hits = searchHits.getHits(); for (SearchHit hit : hits) { String json = hit.getSourceAsString(); ItemDoc itemDoc = JSONUtil.toBean(json, ItemDoc.class); System.out.println("itemDoc = " + itemDoc); } }}排序和分页
与query类似,排序和分页参数都是基于request.source()来设置
DSL和JavaAPI的对比如下:
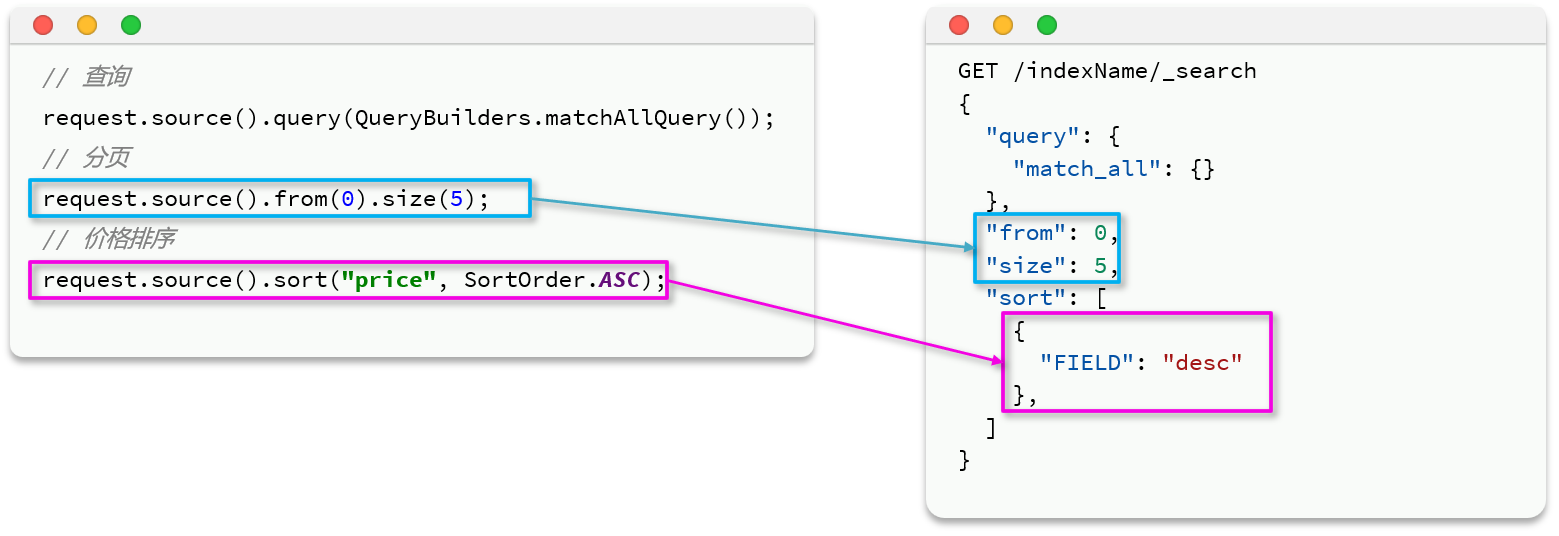
示例:
@Test void testSortAndPage() throws IOException { int pageNum = 1, pageSize = 5; // 1. 创建request对象 SearchRequest request = new SearchRequest("items"); // 2. query条件 request.source().query(QueryBuilders.matchAllQuery()); // 分页 request.source().from((pageNum - 1) * pageSize).size(pageSize); // 排序 request.source().sort("sold", SortOrder.DESC) // 销量降序 .sort("price", SortOrder.ASC); // 价格升序 // 3.发送请求 SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT); // 4. 解析结果 parseResponseResult(response); }高亮显示
高亮查询与前面的查询有两点不同:
- 条件同样是在
request.source()中指定,只不过高亮条件要基于HighlightBuilder来构造 - 高亮响应结果与搜索的文档结果不在一起,需要单独解析
首先来看高亮条件构造,其DSL和JavaAPI的对比如图:
高亮显示的条件构造API如下:
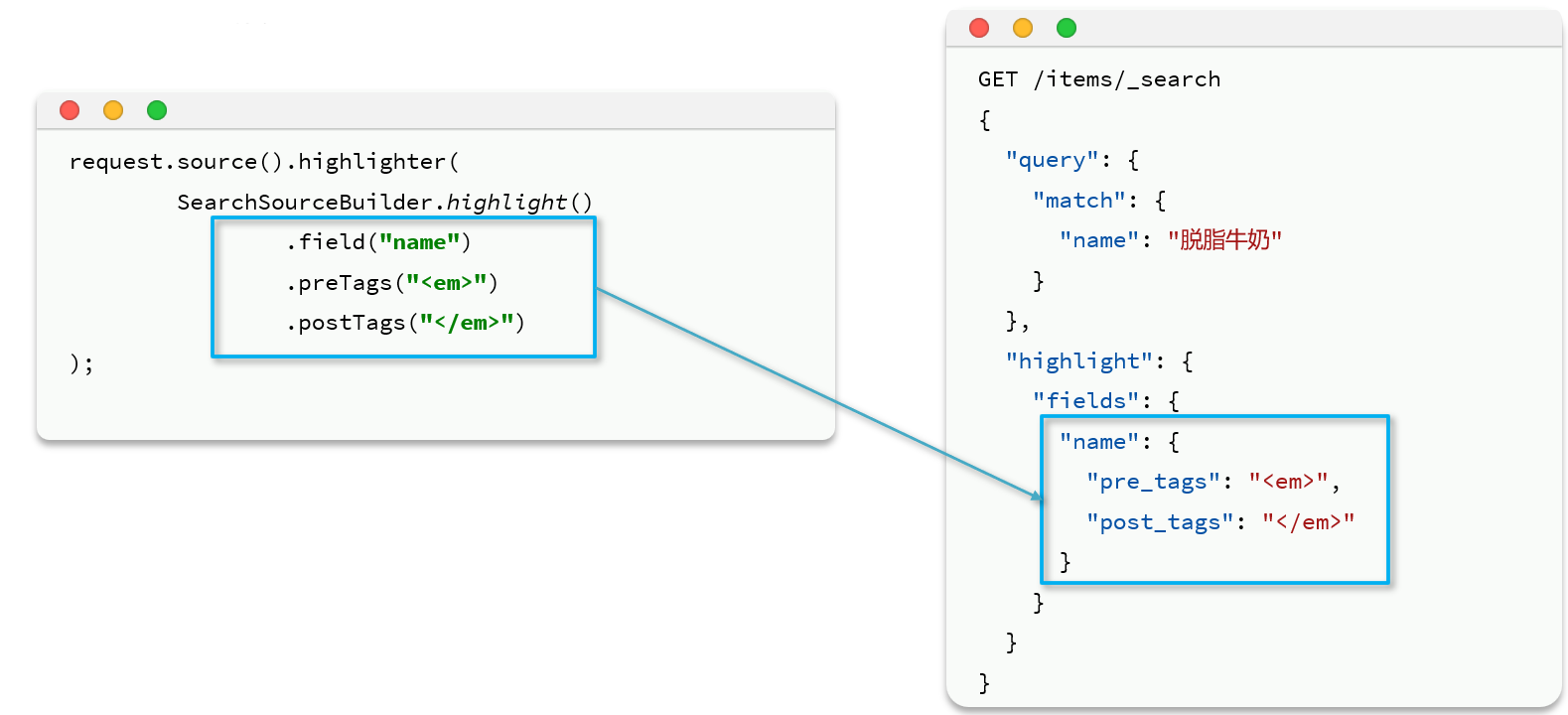
示例代码如下:
@Test void testHighlight() throws IOException { // 1. 创建request对象 SearchRequest request = new SearchRequest("items"); // 2. query条件 request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶")); // 高亮条件 默认就是em标签 request.source().highlighter(SearchSourceBuilder.highlight().field("name").preTags("<em>").postTags("</em>")); // 3.发送请求 SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT); // 4. 解析结果 parseResponseResult(response); }再来看结果解析,文档解析的部分不变,主要是高亮内容需要单独解析出来,其DSL和JavaAPI的对比如图:
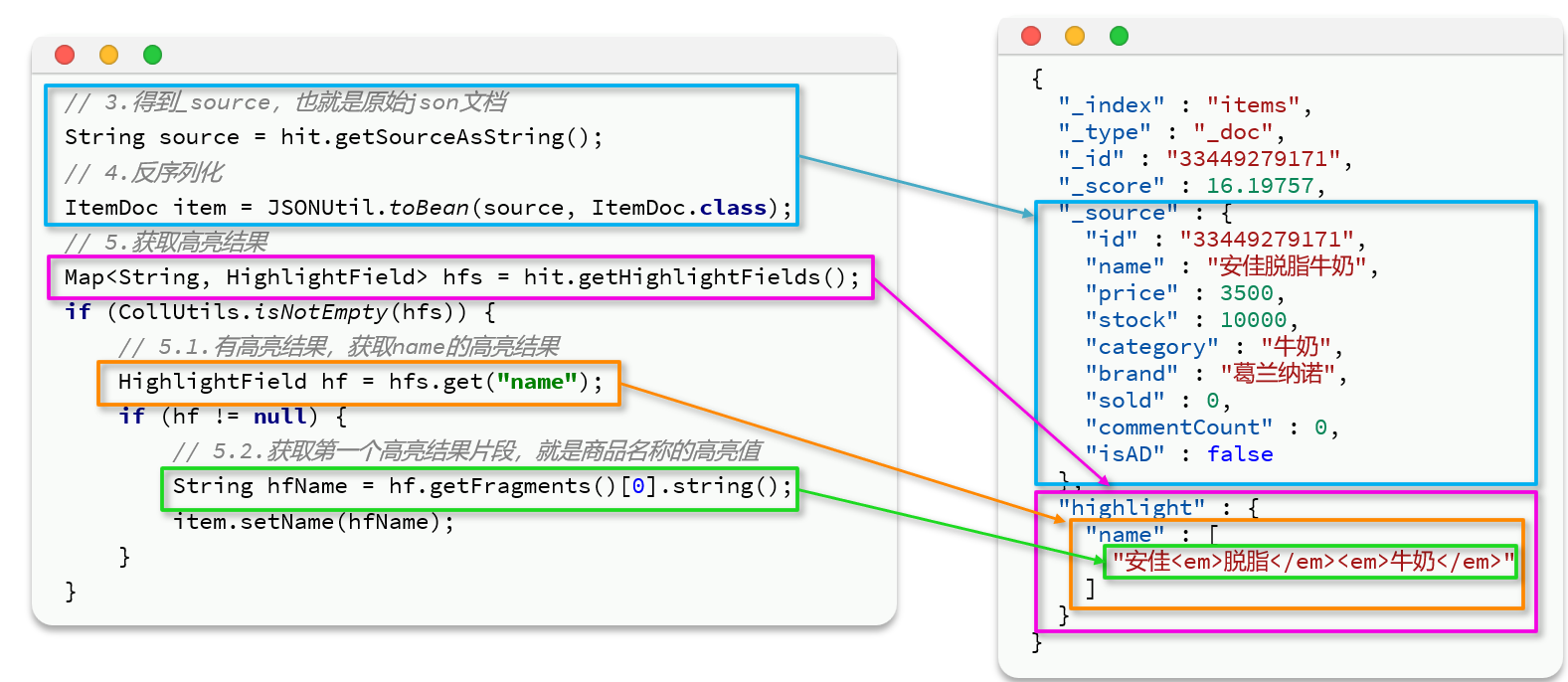
代码解读:
- 第3、4步:从结果中获取
_source。hit.getSourceAsString(),这部分是非高亮结果,json字符串。还需要反序列为ItemDoc对象 - 第5步:获取高亮结果。
hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值 - 第5.1步:从Map中根据高亮字段名称,获取高亮字段值对象
HighlightField - 第5.2步:从
HighlightField中获取Fragments,并且转为字符串。这部分就是真正的高亮字符串了 - 最后:用高亮的结果替换
ItemDoc中的非高亮结果
完整代码如下:
@Test void testHighlight() throws IOException { // 1. 创建request对象 SearchRequest request = new SearchRequest("items"); // 2. query条件 request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶")); // 高亮条件 默认就是em标签 request.source().highlighter(SearchSourceBuilder.highlight().field("name").preTags("<em>").postTags("</em>")); // 3.发送请求 SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT); // 4. 解析结果 SearchHits searchHits = response.getHits(); // 总条数 long total = searchHits.getTotalHits().value; System.out.println("total = " + total); // 命中的数据 SearchHit[] hits = searchHits.getHits(); for (SearchHit hit : hits) { String json = hit.getSourceAsString(); ItemDoc itemDoc = JSONUtil.toBean(json, ItemDoc.class); // 处理高亮结果 Map<String, HighlightField> hfs = hit.getHighlightFields(); if (hfs != null && !hfs.isEmpty()) { // 根据高亮字段名,获取高亮结果 HighlightField hf = hfs.get("name"); // 覆盖高亮结果 String hfName = hf.getFragments()[0].string(); itemDoc.setName(hfName); } System.out.println("itemDoc = " + itemDoc); } }WARNING
String hfName = hf.getFragments()[0].string();这里简写了,如果查询字段的字符串超过一个阈值则会切割这个字符串为几个片段保存在高亮数组中,实际情况需要遍历拼接这个数组中的内容,最终组成一个字符串
数据聚合
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何? 实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
官方文档:文档
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
TermAggregation:按照文档字段值分组Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组 - 度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
Avg:求平均值
Max:求最大值
Min:求最小值
Stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:其它聚合的结果为基础做聚合
::: tip 注意:参加聚合的字段必须是keyword、日期、数值、布尔类型;(不分词的字段) :::
DSL聚合
Bucket聚合
例如我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category值一样的放在同一组,属于Bucket聚合中的Term聚合。
基本语法如下:
GET /items/_search{ "size": 0, "aggs": { "category_agg": { "terms": { "field": "category", "size": 20 } } }}语法说明:
- size:设置size为0,就是每页查0条,则结果中就不包含文档,只包含聚合
- aggs:定义聚合
- category_agg:聚合名称,自定义,但不能重复
- terms:聚合的类型,按分类聚合,所以用term
- field:参与聚合的字段名称
- size:希望返回的聚合结果的最大数量
- terms:聚合的类型,按分类聚合,所以用term
- category_agg:聚合名称,自定义,但不能重复
聚合三要素:名称、类型、字段
示例:
GET /items/_search{ "size": 0, "aggs": { "cate_agg": { "terms": { "field": "category", "size": 5 } }, "brand_agg":{ "terms": { "field": "brand", "size": 5 } } }}响应结果
{ "took" : 16, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 10000, "relation" : "gte" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "brand_agg" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 73002, "buckets" : [ { "key" : "华为", "doc_count" : 7145 }, { "key" : "南极人", "doc_count" : 2432 }, { "key" : "奥古狮登", "doc_count" : 2035 }, { "key" : "森马", "doc_count" : 2005 }, { "key" : "恒源祥", "doc_count" : 1856 } ] }, "cate_agg" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 7583, "buckets" : [ { "key" : "休闲鞋", "doc_count" : 20612 }, { "key" : "牛仔裤", "doc_count" : 19611 }, { "key" : "老花镜", "doc_count" : 16222 }, { "key" : "拉杆箱", "doc_count" : 14347 }, { "key" : "手机", "doc_count" : 10100 } ] } }}
带条件聚合
默认情况下,Bucket聚合是对索引库的所有文档做聚合
但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。 例如,我想知道价格高于3000元的手机品牌有哪些,该怎么统计呢? 我们需要从需求中分析出搜索查询的条件和聚合的目标:
- 搜索查询条件:
- 价格高于3000
- 必须是手机
- 聚合目标:统计的是品牌,肯定是对
brand字段做term聚合
语法如下:
GET /items/_search{ "size": 0, "query": { "bool": { "filter": [ { "term": { "category": "手机" } }, { "range": { "price": { "gte": 300000 } } } ] } }, "aggs": { "brand_agg": { "terms": { "field": "brand", "size": 10 } } }}响应:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 11, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "brand_agg" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "Apple", "doc_count" : 7 }, { "key" : "华为", "doc_count" : 2 }, { "key" : "三星", "doc_count" : 1 }, { "key" : "小米", "doc_count" : 1 } ] } }}Metric聚合
我们统计了价格高于3000的手机品牌,形成了一个个桶。现在我们需要对桶内的商品做运算,获取每个品牌价格的最小值、最大值、平均值。
这就要用到Metric聚合了,例如stat聚合,就可以同时获取min、max、avg等结果。
语法如下:
GET /items/_search{ "size": 0, "query": { "bool": { "filter": [ { "term": { "category": "手机" } } ] } }, "aggs": { "brand_agg": { "terms": { "field": "brand", "size": 5 }, "aggs": { "price_stats": { "stats": { "field": "price" } } } } }}响应:
{ "took" : 7, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 10000, "relation" : "gte" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "brand_agg" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 547, "buckets" : [ { "key" : "华为", "doc_count" : 7145, "price_stats" : { "count" : 7145, "min" : 0.0, "max" : 544000.0, "avg" : 50073.561931420576, "sum" : 3.577756E8 } }, { "key" : "小米", "doc_count" : 1227, "price_stats" : { "count" : 1227, "min" : 200.0, "max" : 889400.0, "avg" : 51005.86797066015, "sum" : 6.25842E7 } }, { "key" : "Apple", "doc_count" : 577, "price_stats" : { "count" : 577, "min" : 100.0, "max" : 688000.0, "avg" : 57975.73656845754, "sum" : 3.3452E7 } }, { "key" : "OPPO", "doc_count" : 430, "price_stats" : { "count" : 430, "min" : 0.0, "max" : 99500.0, "avg" : 50212.558139534885, "sum" : 2.15914E7 } }, { "key" : "vivo", "doc_count" : 174, "price_stats" : { "count" : 174, "min" : 0.0, "max" : 99800.0, "avg" : 52264.36781609195, "sum" : 9094000.0 } } ] } }}可以看到我们在brand_agg聚合的内部,我们新加了一个aggs参数。这个聚合就是brand_agg的子聚合,会对brand_agg形成的每个桶中的文档分别统计。
price_stats:聚合名称- stats:聚合类型,stats是metric聚合的一种
- field:聚合字段,这里选择price,统计价格
- stats:聚合类型,stats是metric聚合的一种
由于stats是对brand_agg形成的每个品牌桶内文档分别做统计,因此每个品牌都会统计出自己的价格最小、最大、平均值。
总结
aggs代表聚合,与query同级,此时query的作用是?
限定聚合的的文档范围
聚合必须的三要素:
聚合名称
聚合类型
聚合字段
聚合可配置属性有:
size:指定聚合结果数量 (聚合结果有多个桶,size可以选择保留多少个桶)
order:指定聚合结果排序方式
field:指定聚合字段
RestClient实现聚合
可以看到在DSL中,aggs聚合条件与query条件是同一级别,都属于查询JSON参数。因此依然是利用request.source()方法来设置。
不过聚合条件的要利用AggregationBuilders这个工具类来构造。DSL与JavaAPI的语法对比如下:
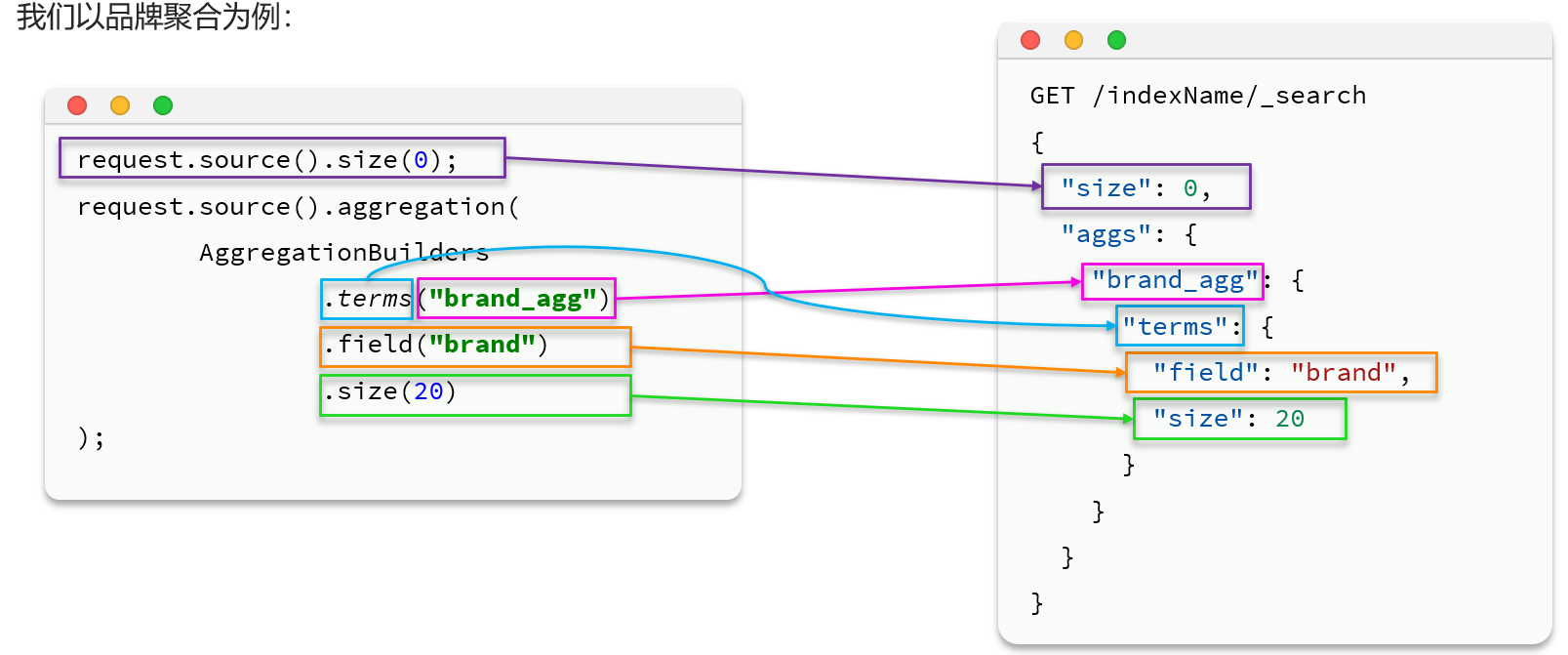
@Test void testAgg() throws IOException { // 1. 创建request对象 SearchRequest request = new SearchRequest("items"); // 2. 分页 request.source().size(0); // 聚合条件 String brandAggName = "brandAgg"; request.source().aggregation( AggregationBuilders.terms(brandAggName) // 类型、名称 .field("brand") // 字段 .size(10) ); // 3.发送请求 SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT); System.out.println("response = " + response); // 4. 解析结果 Aggregations aggregations = response.getAggregations(); // 总条数 Terms brandTerms = aggregations.get(brandAggName); List<? extends Terms.Bucket> buckets = brandTerms.getBuckets(); for (Terms.Bucket bucket : buckets) { String keyAsString = bucket.getKeyAsString(); long docCount = bucket.getDocCount(); System.out.println("brand = " + keyAsString); System.out.println("count = " + docCount); } }结果:
{ "took": 21, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 10000, "relation": "gte" }, "max_score": null, "hits": [] }, "aggregations": { "sterms#brandAgg": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 65272, "buckets": [ { "key": "华为", "doc_count": 7145 }, { "key": "南极人", "doc_count": 2432 }, { "key": "奥古狮登", "doc_count": 2035 }, { "key": "森马", "doc_count": 2005 }, { "key": "恒源祥", "doc_count": 1856 }, { "key": "回力", "doc_count": 1695 }, { "key": "其他品牌", "doc_count": 1590 }, { "key": "斯凯奇", "doc_count": 1565 }, { "key": "小米", "doc_count": 1498 }, { "key": "北极绒", "doc_count": 1382 } ] } }}
brand = 华为count = 7145brand = 南极人count = 2432brand = 奥古狮登count = 2035brand = 森马count = 2005brand = 恒源祥count = 1856brand = 回力count = 1695brand = 其他品牌count = 1590brand = 斯凯奇count = 1565brand = 小米count = 1498brand = 北极绒count = 1382评论区
评论区加载中...
如果长时间无法显示,请尝试刷新页面。